
Yocto 项目是一个开源项目,它为嵌入式 Linux 系统的开发人员提供了一个共同的起点,以便在硬件无关的环境中为嵌入式产品创建定制的发行版。由 Linux 基金会赞助的 Yocto 项目不仅仅是一个构建系统。它提供了工具、流程、模板和方法,使开发人员能够快速创建和部署面向嵌入式市场的产品。Yocto 项目的核心组件之一是 Poky 构建系统。由于 Poky 是一个大型而复杂的系统,因此我们将重点关注其核心组件之一 BitBake。BitBake 是一款受 Gentoo-Portage 启发的构建工具,Yocto 项目和 OpenEmbedded 社区都使用它来利用元数据从源代码创建 Linux 映像。
2001 年,夏普公司推出了名为 Zaurus 的 SL-5000 PDA,它运行了一个名为 Lineo 的嵌入式 Linux 发行版。在 Zaurus 推出后不久,Chris Larson 创办了 OpenZaurus 项目,这是一个基于名为 buildroot 的构建系统的 SharpROM 替代 Linux 发行版。随着项目的成立,人们开始贡献更多软件包,以及其他设备的目标,并且不久之后,OpenZaurus 的构建系统就开始显示出脆弱性。2003 年 1 月,社区开始讨论一个新的构建系统,以将嵌入式 Linux 发行版的通用构建系统的社区使用模型整合到其中。这最终将成为 OpenEmbedded。Chris Larson、Michael Lauer 和 Holger Schurig 开始着手 OpenEmbedded,将数百个 OpenZaurus 包移植到新的构建系统中。
Yocto 项目起源于此工作。该项目的核心是 Richard Purdie 创建的 Poky 构建系统。它最初是 OpenEmbedded 的一个稳定分支,使用数千个 OpenEmbedded 规范的内核子集,涵盖有限的架构集。随着时间的推移,它逐渐演变为不仅仅是一个嵌入式构建系统,而是一个完整的软件开发平台,包括 Eclipse 插件、fakeroot 替代品和基于 QEMU 的映像。2010 年 11 月左右,Linux 基金会宣布,所有这些工作将继续在 Yocto 项目的标题下进行,作为 Linux 基金会赞助的项目。之后,Yocto 项目和 OpenEmbedded 将协调一套名为 OE-Core 的核心包元数据,将 Poky 和 OpenEmbedded 的精华结合起来,并更多地使用分层结构来添加其他组件。
Poky 构建系统是 Yocto 项目的核心。在 Poky 的默认配置中,它可以提供一个从可访问 shell 的最小映像到符合 Linux 标准库的映像(包含基于 GNOME Mobile and Embedded(GMAE)的参考用户界面,称为 Sato)的起始映像占用空间。从这些基本映像类型开始,可以添加元数据层以扩展功能;层可以为映像类型提供额外的软件堆栈、为其他硬件添加板级支持包 (BSP),甚至表示新的映像类型。使用 Poky 的 1.1 版本(名为“edison”),我们将展示 BitBake 如何使用这些规范和配置文件生成嵌入式映像。
从非常高的层面上讲,构建过程从为构建运行设置 shell 环境开始。这通过引用位于 Poky 源代码树根目录下的文件 oe-init-build-env 来完成。这将设置 shell 环境、创建一组最初的可定制配置文件,并将 BitBake 运行时与 Poky 用于确定是否满足最小系统要求的 shell 脚本包装在一起。
例如,它将查找的其中一件事是 Pseudo 的存在,Pseudo 是 Wind River Systems 贡献给 Yocto 项目的 fakeroot 替代品。此时,例如,bitbake core-image-minimal 应该能够创建一个功能齐全的交叉编译环境,然后根据 Yocto 项目元数据层中定义的 core-image-minimal 的映像定义从源代码创建 Linux 映像。
在创建映像期间,BitBake 将解析其配置,包括任何定义的附加层、类、任务或规范,并从创建加权依赖关系链开始。此过程提供了一个有序且加权的任务优先级映射。然后,BitBake 使用此映射来确定必须按什么顺序构建哪些包,以便最有效地满足编译依赖关系。大多数其他任务需要的任务权重更高,因此在构建过程的早期运行。创建了构建的任务执行队列。BitBake 还存储解析的元数据摘要,如果在后续运行中它确定元数据已更改,则它可以仅重新解析已更改的部分。BitBake 调度程序和解析器是 BitBake 中一些更有趣的架构设计,有关它们及其由 BitBake 贡献者实现的决策的一些讨论将在后面进行。
然后,BitBake 遍历其加权任务队列,生成线程(数量由 conf/local.conf 中的 BB_NUMBER_THREADS 定义),这些线程开始按预先确定的顺序执行这些任务。在包的构建期间执行的任务可能会被修改、在前面添加或在后面添加,这可以通过其规范来完成。基本、默认的包任务执行顺序从获取和解压缩包源代码开始,然后配置和交叉编译解压缩的源代码。然后,编译后的源代码被分成包,并对编译结果进行各种计算,例如创建调试包信息。然后,拆分的包被打包成受支持的包格式;支持 RPM、ipk 和 deb。然后,BitBake 将使用这些包来构建根文件系统。
Poky 构建系统最强大的特性之一是,构建的每个方面都由元数据控制。元数据可以大体上分为配置文件或包规范。规范是 BitBake 用于设置变量或定义额外构建时任务的不可执行元数据的集合。规范包含字段,例如规范说明、规范版本、包许可证和上游源代码存储库。它还可以指示构建过程使用 autotools、make、distutils 或任何其他构建过程,在这种情况下,基本功能可以通过它从 OE-Core 层的 ./meta/classes 中的类定义继承的类来定义。还可以定义其他任务,以及任务先决条件。BitBake 还支持 _prepend 和 _append 作为通过将使用 prepend 或 append 后缀指示的代码注入任务的开头或结尾来扩展任务功能的方法。
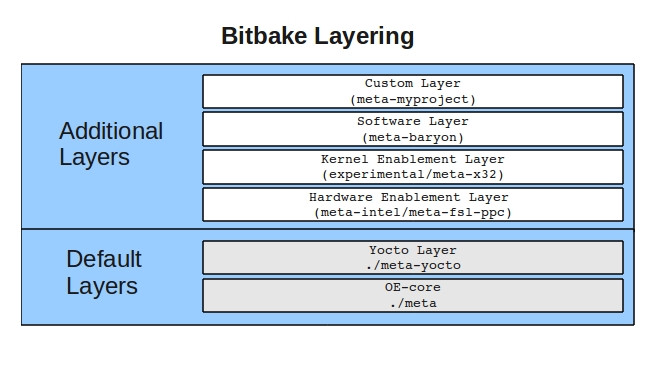
配置文件可以分为两种类型。一种是配置 BitBake 和整个构建运行,另一种是配置 Poky 用于创建目标映像的不同配置的各种层。层是任何提供某种额外功能的元数据分组。这些可以是新设备的 BSP、额外的映像类型或核心层之外的额外软件。事实上,核心 Yocto 项目元数据 meta-yocto 本身就是一个应用于 OE-Core 元数据层 meta 之上的层,它为 OE-Core 层添加了额外的软件和映像类型。
例如,如何使用分层结构来为英特尔 n660(Crownbay)创建 NAS 设备,使用 x32(x86-64 的新的 32 位原生 ABI),并使用一个自定义软件层来添加用户界面。
鉴于手头的任务,我们可以将此功能分成几层。在最低级别,我们将使用 Crownbay 的 BSP 层来启用 Crownbay 特定的硬件功能,例如视频驱动程序。由于我们想要 x32,我们将使用实验性的 meta-x32 层。NAS 功能将通过添加 Yocto 项目的示例 NAS 层 meta-baryon 来构建在其之上。最后,我们将使用一个名为 meta-myproject 的虚构层来提供创建 NAS 配置图形用户界面的软件和配置。
在设置 BitBake 环境期间,通过引用 oe-build-init-env 会生成一些初始配置文件。这些配置文件让我们可以很好地控制 Poky 生成的内容和方式。这些配置文件中的第一个是 bblayers.conf。我们将使用此文件来添加其他层以构建我们的示例项目。
以下是一个 bblayers.conf 文件的示例
# LAYER_CONF_VERSION is increased each time build/conf/bblayers.conf # changes incompatibly LCONF_VERSION = "4" BBFILES ?= "" BBLAYERS = " \ /home/eflanagan/poky/meta \ /home/eflanagan/poky/meta-yocto \ /home/eflanagan/poky/meta-intel/crownbay \ /home/eflanagan/poky/meta-x32 \ /home/eflanagan/poky/meta-baryon\ /home/eflanagan/poky/meta-myproject \ "
BitBake 层文件 bblayers 定义了一个变量 BBLAYERS,BitBake 使用它来查找 BitBake 层。为了完全理解这一点,我们还应该看看我们的层是如何实际构建的。以 meta-baryon (git://git.yoctoproject.org/meta-baryon) 作为我们的示例层,我们要检查层配置文件。这个文件 conf/layer.conf 是 BitBake 在其最初解析 bblayers.conf 后解析的内容。从这里开始,它会将额外的规范、类和配置添加到构建中。
以下是 meta-baryon 的 layer.conf
# Layer configuration for meta-baryon layer
# Copyright 2011 Intel Corporation
# We have a conf directory, prepend to BBPATH to prefer our versions
BBPATH := "${LAYERDIR}:${BBPATH}"
# We have recipes-* directories, add to BBFILES
BBFILES := "${BBFILES} ${LAYERDIR}/recipes-*/*/*.bb ${LAYERDIR}/recipes-*/*/*.bbappend"
BBFILE_COLLECTIONS += "meta-baryon"
BBFILE_PATTERN_meta-baryon := "^${LAYERDIR}/"
BBFILE_PRIORITY_meta-baryon = "7"
所有 BitBake 配置文件都有助于生成 BitBake 的数据存储,该数据存储在创建任务执行队列期间使用。在构建开始时,BitBake 的 BBCooker 类启动。cooker 通过烘焙规范来管理构建任务执行。cooker 做的第一件事之一就是尝试加载和解析配置数据。请记住,BitBake 正在查找两种类型的配置数据。为了告诉构建系统应该在哪里找到这些配置数据(进而在哪里找到规范元数据),cooker 的 parseConfigurationFiles 方法被调用。除了一些例外,cooker 查找的第一个配置文件是 bblayers.conf。解析此文件后,BitBake 随后解析每个层的 layer.conf 文件。
解析完层配置文件后,parseConfigurationFiles 随后解析 bitbake.conf,其主要目的是设置全局构建时变量,例如各种 rootfs 目录的目录结构命名以及编译时使用的初始 LDFLAGS。大多数最终用户永远不会接触到这个文件,因为这里需要更改的大多数内容都在规范上下文中,而不是构建范围,或者可以在配置文件(例如 local.conf)中覆盖。
在解析此文件时,BitBake 还包含相对于 BBLAYERS 中的每个层的配置文件,并将这些文件中找到的变量添加到其数据存储中。
以下是 bitbake.conf 的一部分,显示了包含的配置文件
include conf/site.conf
include conf/auto.conf
include conf/local.conf
include conf/build/${BUILD_SYS}.conf
include conf/target/${TARGET_SYS}.conf
include conf/machine/${MACHINE}.conf
grep 的示例 BitBake 规范DESCRIPTION = "GNU grep utility"
HOMEPAGE = "http://savannah.gnu.org/projects/grep/"
BUGTRACKER = "http://savannah.gnu.org/bugs/?group=grep"
SECTION = "console/utils"
LICENSE = "GPLv3"
LIC_FILES_CHKSUM = "file://COPYING;md5=8006d9c814277c1bfc4ca22af94b59ee"
PR = "r0"
SRC_URI = "${GNU_MIRROR}/grep/grep-${PV}.tar.gz"
SRC_URI[md5sum] = "03e3451a38b0d615cb113cbeaf252dc0"
SRC_URI[sha256sum]="e9118eac72ecc71191725a7566361ab7643edfd3364869a47b78dc934a357970"
inherit autotools gettext
EXTRA_OECONF = "--disable-perl-regexp"
do_configure_prepend
() {
rm
-f ${S}/m4/init.m4
}
do_install () {
autotools_do_install
install -d ${D}${base_bindir}
mv ${D}${bindir}/grep ${D}${base_bindir}/grep.${PN}
mv ${D}${bindir}/egrep ${D}${base_bindir}/egrep.${PN}
mv ${D}${bindir}/fgrep ${D}${base_bindir}/fgrep.${PN}
}
pkg_postinst_${PN}() {
update-alternatives --install ${base_bindir}/grep grep grep.${PN} 100
update-alternatives --install ${base_bindir}/egrep egrep egrep.${PN} 100
update-alternatives --install ${base_bindir}/fgrep fgrep fgrep.${PN} 100
}
pkg_prerm_${PN}() {
update-alternatives --remove grep grep.${PN}
update-alternatives --remove egrep egrep.${PN}
update-alternatives --remove fgrep fgrep.${PN}
}
在深入探讨 BitBake 的当前架构设计之前,了解 BitBake 过去的工作原理会有所帮助。为了充分理解 BitBake 的发展历程,我们将回顾其最初版本,即 BitBake 1.0。在 BitBake 的第一个版本中,构建的依赖关系链是根据配方依赖关系确定的。如果在构建映像的过程中出现错误,BitBake 会继续执行下一个任务,并在稍后尝试重新构建它。显然,这意味着构建需要很长时间。BitBake 还做的一件事是将每个配方使用的所有变量都保存在一个非常大的字典中。考虑到配方数量以及完成构建所需的变量和任务数量,BitBake 1.0 非常消耗内存。在内存昂贵且系统内存较少的时代,构建过程可能是痛苦的。系统在执行长时间运行的构建时耗尽内存(写入交换空间)的情况并不少见。在最初的版本中,虽然它能够完成任务(有时),但它的速度很慢,并且消耗了大量的资源。更糟糕的是,由于 BitBake 1.0 没有数据持久化缓存或共享状态的概念,因此它也无法进行增量构建。如果构建失败,必须从头开始重新构建。
快速比较 Poky “edison” 1.13.3 和 1.0 中使用的当前 BitBake 版本,可以发现 BitBake 的客户端-服务器架构、数据持久化缓存、数据存储、数据存储的写时复制改进、共享状态实现以及任务和包依赖关系链确定方式的重大改进。这些改进使 BitBake 更加可靠、高效和动态。这些功能的许多改进都是出于对更快速、更可靠的构建的需求,这些构建使用更少的资源。我们将考察的 BitBake 的三个改进是客户端-服务器架构的实现、围绕 BitBake 数据存储的优化以及 BitBake 确定其构建和任务依赖关系链所做的工作。
现在我们已经了解 Poky 构建系统如何使用配置、配方和层来创建嵌入式映像,我们准备开始深入研究 BitBake 的内部机制,并检查这些机制是如何结合在一起的。从核心 BitBake 可执行文件 `bitbake/bin/bake` 开始,我们可以开始了解 BitBake 在开始设置构建所需的基础设施时所遵循的过程。第一个值得关注的项目是 BitBake 的进程间通信 (IPC)。最初,BitBake 没有客户端-服务器的概念。这个功能是在一段时间内逐步融入 BitBake 设计的,目的是允许 BitBake 在构建过程中运行多个进程(因为 BitBake 最初是单线程的),并允许不同的用户体验。
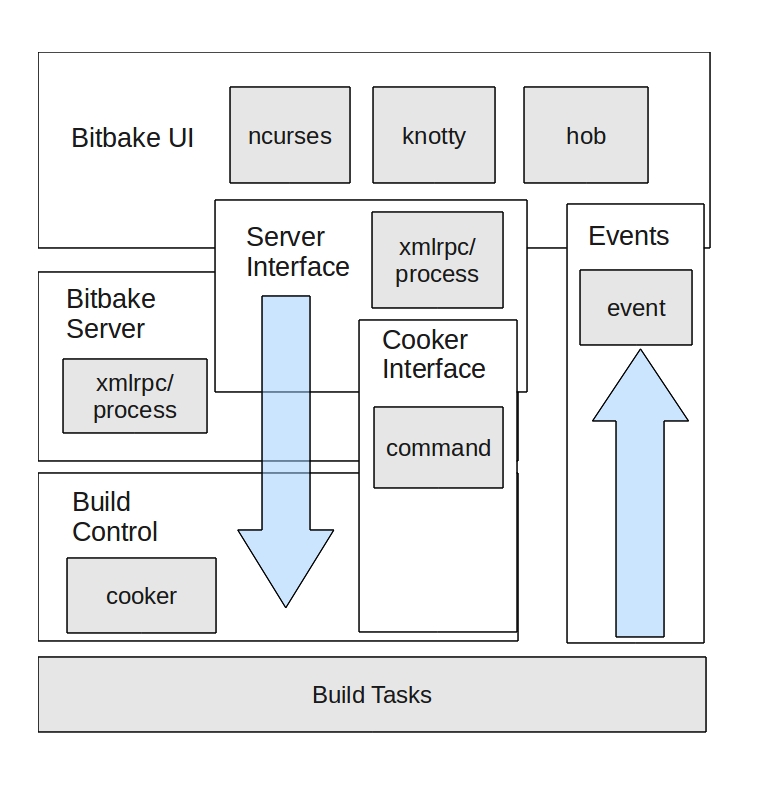
所有 Poky 构建都是通过启动一个用户界面实例开始的。用户界面提供了构建输出、构建状态和构建进度的日志记录机制,以及通过 BitBake 事件模块从构建任务接收事件的功能。默认的用户界面是 `knotty`,即 BitBake 的命令行界面。`knotty` 的名称来源于 “(no) tty”,因为它同时处理 tty 和非 tty,它是支持的几个界面之一。这些额外的用户界面之一是 Hob。Hob 是 BitBake 的图形界面,一种 “BitBake 指挥官”。除了在 `knotty` 用户界面中看到的典型功能之外,Hob(由 Joshua Lock 编写)还带来了修改配置文件、添加额外的层和包以及完全自定义构建的功能。
BitBake 用户界面能够向 BitBake 可执行文件调用的下一个模块(BitBake 服务器)发送命令。与用户界面类似,BitBake 也支持多种不同的服务器类型,例如 XMLRPC。大多数用户在从 `knotty` 用户界面执行 BitBake 时使用的默认服务器是 BitBake 的进程服务器。启动服务器后,BitBake 可执行文件会启动 `cooker`。
`cooker` 是 BitBake 的核心部分,大多数在 Poky 构建过程中发生的有趣的事情都是从这里调用的。`cooker` 管理元数据的解析、启动依赖关系树和任务树的生成,并管理构建。BitBake 服务器架构的功能之一是允许以多种方式将命令 API 间接公开给用户界面。命令模块是 BitBake 的工作者,它运行构建命令并触发事件,这些事件通过 BitBake 的事件处理器传递到用户界面。启动 `cooker` 后,它会初始化 BitBake 数据存储,然后开始解析所有 Poky 的配置文件。然后,它会创建 `runqueue` 对象并触发构建。
在 BitBake 1.0 中,所有 BitBake 变量都在该版本数据类的初始化过程中被解析并存储在一个非常大的字典中。如前所述,这存在问题,因为非常大的 Python 字典在写入和成员访问方面速度很慢,如果构建主机在构建过程中耗尽物理内存,最终就会使用交换空间。虽然这在 2011 年末大多数系统中不太可能发生,但当时 OpenEmbedded 和 BitBake 刚刚起步,平均计算机的配置通常只有不到 1 或 2 GB 的内存。
这是早期 BitBake 中的主要痛点之一。为了提高性能,需要解决两个主要问题:一个是构建依赖关系链的预计算;另一个是减少存储在内存中的数据大小。存储在配方中的许多数据在不同的配方之间不会改变;例如,对于 `TMPDIR`、`BB_NUMBER_THREADS` 和其他全局 BitBake 变量,每个配方都存储整个数据环境的副本,效率很低。解决方案是 Tom Ansell 的写时复制字典,它 “利用类来实现高效和快速”。BitBake 的 COW 模块既大胆又巧妙。运行 `python BitBake/lib/bb/COW.py` 并检查该模块,可以了解这种写时复制实现的工作原理以及 BitBake 如何使用它来高效地存储数据。
DataSmart 模块使用 COW 字典,将来自初始 Poky 配置、`.conf` 文件和 `.bbclass` 文件的数据存储在一个字典中,作为数据对象。每个对象都可以包含另一个数据对象,该对象只包含数据的差异。因此,如果一个配方更改了初始数据配置中的某些内容,则它不会为了本地化而复制整个配置,而是将父数据对象的差异存储在 COW 堆栈中的下一层。当尝试访问变量时,数据模块会使用 DataSmart 查看堆栈的顶层。如果找不到变量,它会向下转到堆栈的下一层,直到找到该变量或抛出错误。
DataSmart 模块的另一个有趣之处在于变量扩展。由于 BitBake 变量可以包含可执行的 Python 代码,因此需要做的一件事是通过 BitBake 的 `bb.codeparser` 运行变量,以确保它是有效的 Python 并且不包含循环引用。以下是从 `./meta/conf/distro/include/tclibc-eglibc.inc` 中获取的包含 Python 代码的变量示例:
LIBCEXTENSION = "${@['', '-gnu'][(d.getVar('ABIEXTENSION', True) or '') != '']}"
此变量从 OE-Core 配置文件 `./meta/conf/distro/include/defaultsetup.conf` 中包含,用于提供一组默认选项,这些选项跨越不同的发行版配置,可以叠加在 Poky 或 OpenEmbedded 之上。该文件导入一些特定于 `eglibc` 的变量,这些变量的值取决于另一个 BitBake 变量 `ABIEXTENSION`。在创建数据存储的过程中,需要解析和验证此变量中的 Python 代码,以确保使用此变量的任务不会失败。
BitBake 解析配置并创建数据存储后,需要解析映像所需的配方并生成构建链。这是对 BitBake 的一项重大改进。最初,BitBake 从配方中获取其构建优先级。如果一个配方具有 `DEPENDS`,它会尝试找出要构建什么才能满足该依赖关系。如果一个任务因为缺少其构建所需的先决条件而失败,它只是被放到一边,并在稍后尝试。这在效率和可靠性方面都有明显的缺点。
由于没有建立预计算的依赖关系链,因此任务执行顺序是在构建运行时确定的。这限制了 BitBake 只能单线程运行。为了说明单线程 BitBake 构建的痛苦程度,2011 年在标准开发机器(英特尔酷睿 i7,16 GB DDR3 内存)上构建最小的映像 “core-image-minimal” 需要大约 3 或 4 个小时才能构建完整的交叉编译工具链并使用它来生成用于创建映像的包。作为参考,在同一台机器上,`BB_NUMBER_THREADS` 设置为 14,`PARALLEL_MAKE` 设置为 “-j 12”,大约需要 30 到 40 分钟。可以想象,在更慢的硬件上,内存更少,并且大量内存被整个数据存储的重复副本浪费,以单线程方式运行,没有预计算的任务执行顺序,需要更长的时间。
当我们谈论构建依赖关系时,我们需要区分各种类型。构建依赖关系或 `DEPENDS` 是 Poky 构建所需包的先决条件,而运行时依赖关系 `RDEPENDS` 要求安装了该包的映像也包含作为 `RDEPENDS` 列出的包。以 `task-core-boot` 包为例。如果查看它在
meta/recipes-core/tasks/task-core-boot.bb
中的配方,我们会看到两个 BitBake 变量被设置:`RDEPENDS` 和 `DEPENDS`。BitBake 在创建其依赖关系链时使用这两个字段。
以下是 `task-core-boot.bb` 的一部分,显示了 `DEPENDS` 和 `RDEPENDS`
DEPENDS = "virtual/kernel" ... RDEPENDS_task-core-boot = "\ base-files \ base-passwd \ busybox \ initscripts \ ...
包不是 BitBake 中唯一具有依赖关系的项目。任务也有自己的依赖关系。在 BitBake 的 `runqueue` 范围内,我们识别出四种类型:内部依赖、`DEPENDS` 依赖、`RDEPENDS` 依赖和任务间依赖。
内部依赖任务是在配方中设置的,并在另一个任务之前和/或之后添加一个任务。例如,在一个配方中,我们可以通过添加行 `addtask deploy before do_build after do_compile` 来添加一个名为 `do_deploy` 的任务。这会添加一个依赖关系,要求在启动 `do_build` 之前运行 `do_deploy` 任务,但在 `do_compile` 完成之后。`DEPENDS` 和 `RDEPENDS` 依赖任务是在指定任务之后运行的任务。例如,如果我们希望在 `DEPENDS` 或 `RDEPENDS` 的 `do_install` 之后运行一个包的 `do_deploy`,我们的配方将包含 `do_deploy[deptask] = 'do_install'` 或 `do_deploy[rdeptask] = 'do_install'`。对于任务间依赖关系,如果我们希望一个任务依赖于另一个包的任务,我们将使用上面 `do_deploy` 的例子添加 `do_deploy[depends] = "<target's name>:do_install"`。
由于一个镜像构建可能包含数百个配方,每个配方包含多个包和任务,每个任务都有自己的依赖关系,BitBake 现在需要将它们排序以便能够执行。当 Cooker 从 `bb.data` 对象的初始化中获得所有需要构建的包列表后,它将开始从这些数据中创建一个加权任务映射,以便生成一个按优先级排序的任务列表,称为 **运行队列(runqueue)**。运行队列创建后,BitBake 就可以开始按优先级执行它,将每个部分分配给不同的线程。
在提供者模块中,BitBake 将首先查看是否存在针对特定包或镜像的 **首选提供者(PREFERRED_PROVIDER)**。由于多个配方可以提供同一个包,并且任务是在配方中定义的,因此 BitBake 需要决定使用哪个包提供者。它将对包的所有提供者进行排序,根据不同的标准对每个提供者进行加权。例如,软件的首选版本将比其他版本优先级更高。然而,BitBake 也考虑了包版本以及其他包的依赖关系。一旦它选择了将从中获取包的配方,BitBake 将迭代该配方的 DEPENDS 和 RDEPENDS,并继续计算这些包的提供者。这种连锁反应将生成一个用于镜像生成的包列表以及这些包的提供者。
运行队列现在拥有一个完整的列表,包括所有需要构建的包和依赖关系链。为了开始构建执行,运行队列模块现在需要创建 **TaskData** 对象,以便它可以开始对加权任务映射进行排序。它首先获取每个可构建的包,将生成该包所需的任务进行拆分,并根据依赖于该任务的包数量对每个任务进行加权。权重越高的任务具有更多依赖项,因此通常在构建的早期阶段执行。完成此操作后,运行队列模块将准备将 TaskData 对象转换为运行队列。
运行队列的创建有些复杂。BitBake 首先遍历 TaskData 对象中的任务名称列表,以确定任务依赖关系。当它遍历 TaskData 时,它开始构建一个加权任务映射。当它完成后,如果它没有找到循环依赖关系、不可构建的任务或任何此类问题,它将按权重对任务映射进行排序,并返回一个完整的运行队列对象到 Cooker。Cooker 将开始尝试按任务执行运行队列。根据镜像大小和计算资源,Poky 可能需要花费半小时到数小时才能生成交叉编译工具链、包提要和指定的嵌入式 Linux 镜像。值得注意的是,从命令行执行 `bitbake <image_name>` 开始,整个过程一直到任务执行队列开始执行之前,只花费了不到几秒钟。
在我与社区成员的讨论以及我自己的个人观察中,我发现了一些应该以不同方式完成的事情,以及一些有价值的经验教训。重要的是要注意,对十年的开发工作进行“事后诸葛亮”式的分析,并不是对那些将时间和精力投入到一个完全非凡的软件集合中的人的批评。作为开发者,我们工作中最困难的部分是预测未来几年我们需要什么,以及如何建立一个框架来支持现在的工作。很少有人能在没有遇到一些挫折的情况下做到这一点。
第一个经验教训是确保制定一份由社区理解并达成一致的书面标准文档。它应该为最大的灵活性和增长而设计。
我个人遇到这个问题的一个地方是我在 OE-Core 的许可证清单创建类中的工作,特别是与我使用 LICENSE 变量的经验。由于没有明确的文档标准规定 LICENSE 应该包含什么,对许多可用配方的审查显示出许多变体。不同的 LICENSE 字符串包含从 Python 抽象语法树可解析的值到几乎无法从中获得有意义数据的各种值。社区中普遍使用一种约定;然而,这种约定有很多变体,有些变体比其他变体更不正确。这不是编写配方的开发者的问题;而是社区未能定义标准。
由于之前很少使用 LICENSE 变量进行除了检查其是否存在之外的操作,因此对于该变量的标准没有特别关注。如果在早期就制定了项目范围内的共识标准,那么很多麻烦都可以避免。
下一个经验教训更笼统,它谈到了不仅仅在 Yocto 项目中,而且在其他大型系统设计特定项目中也存在的问题。它是开发者可以做到的最重要的事情之一,可以限制项目遇到的工作量重复、重构和翻新:花时间——大量时间——进行前端规划和架构设计。
如果你认为你已经花足够的时间进行架构设计了,那么你可能还没有。如果你认为你还没有花足够的时间进行架构设计,那么你肯定还没有。在前端规划上花费更多时间不会阻止你以后不得不拆开代码,甚至进行重大架构变更,但它肯定会从长远来看减少重复工作的数量。
将你的软件设计得尽可能模块化,知道你最终会回到某些区域进行从微调到重写的所有操作,这样当你遇到这些问题时,代码重写就不会那么让人头疼。
在 Yocto 项目中,这方面显而易见的一个地方是识别低内存系统终端用户的需求。如果早些时候对 BitBake 的数据存储进行了更多思考,也许我们可以预测与数据存储占用过多内存相关的问题,并更早地解决它。
这里的经验教训是,虽然几乎不可能识别出项目在其生命周期中将遇到的所有痛点,但花时间进行认真地前端规划将有助于减少以后所需的努力。BitBake、OE-Core 和 Yocto 项目在这方面都很幸运,因为在早期进行了相当多的架构规划。这使我们能够对架构进行重大更改,而不会造成太多痛苦和煎熬。
首先,感谢 Chris Larson、Michael Lauer 和 Holger Schurig,以及多年来为 BitBake、OpenEmbedded、OE-Core 和 Yocto 项目做出贡献的许多许多人。也要感谢 Richard Purdie 让我向他请教 OE 的历史和技术方面,以及他不断的鼓励和指导,特别是在 BitBake 的一些黑魔法方面。