Yesod 是用 Haskell 编程语言编写的 Web 框架。虽然许多流行的 Web 框架利用了其宿主语言的动态特性,但 Yesod 利用了 Haskell 的静态特性来生成更安全、更快的代码。
Yesod 的开发始于大约两年前,并且一直在蓬勃发展。Yesod 在现实项目中磨练了其技能,其所有初始功能都源于实际的、现实生活中的需求。起初,开发几乎完全是一个人的事。经过大约一年的开发,社区的努力开始发挥作用,Yesod 从那时起已发展成为一个蓬勃发展的开源项目。
在胚胎阶段,当 Yesod 非常短暂且定义不清时,试图让一个团队来开发它将是适得其反的。到它稳定到足以对其他人有用的时候,正是时候找出一些决策的弊端了。从那时起,我们对用户界面 API 做出了重大改变,使其更加有用,并且正在快速巩固 1.0 版本的发布。
你可能会问的问题是:为什么又要另一个 Web 框架?让我们改而转向另一个问题:为什么使用 Haskell?似乎世界上大多数人都对两种语言风格之一感到满意
这是一个错误的二分法。静态类型语言没有理由变得如此笨拙。Haskell 能够捕获 Ruby 和 Python 的大量表达能力,同时仍然保持强类型语言。事实上,Haskell 的类型系统比 Java 及其同类产品捕获了更多错误。空指针异常被完全消除;不可变的数据结构简化了对代码的推理,并简化了并行和并发编程。
那么为什么选择 Haskell?它是一种高效、开发人员友好的语言,提供了许多编译时程序正确性检查。
Yesod 的目标是将 Haskell 的优势扩展到 Web 开发中。Yesod 努力使您的代码尽可能简洁。只要有可能,您的每一行代码都会在编译时进行正确性检查。它不需要大量的单元测试库来测试基本属性,编译器会为您完成所有工作。在表面之下,Yesod 使用了我们能找到的尽可能多的高级性能技术,让您的高级代码飞起来。
总的来说,Yesod 与领先框架(如 Rails 和 Django)更相似,而不是不同。它通常遵循模型-视图-控制器(MVC)范式,具有将视图与逻辑分离的模板系统,提供了一个对象关系映射(ORM)系统,并采用前端控制器方法进行路由。
魔鬼藏在细节中。Yesod 努力将尽可能多的错误捕获推到编译阶段,而不是运行时,并通过类型系统自动捕获错误和安全漏洞。虽然 Yesod 试图保持一个用户友好、高级的 API,但它使用来自函数式编程世界的许多新技术来实现高性能,并且不怕向开发人员公开这些内部细节。
Yesod 中的主要架构挑战是平衡这两个看似冲突的目标。例如,Yesod 的 路由方法(称为类型安全 URL)并没有什么革命性。从历史上看,实现这种解决方案是一个繁琐且容易出错的过程。Yesod 的创新在于使用模板 Haskell(一种代码生成形式)来自动化启动该过程所需的样板代码。类似地,类型安全的 HTML 已经存在很久了;Yesod 试图保持常用模板语言的用户友好性,同时保留类型安全性的强大功能。
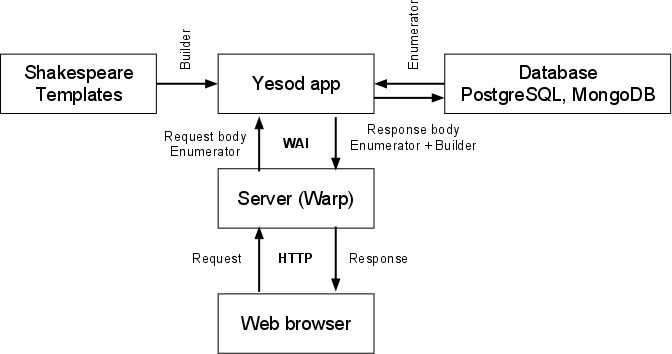
Web 应用程序需要某种方法与服务器通信。一种可能的方法是将服务器直接嵌入到框架中,但这必然会限制您的部署选项并导致接口不佳。许多语言都创建了标准接口来解决这个问题:Python 有 WSGI,Ruby 有 Rack。在 Haskell 中,我们有 WAI:Web 应用程序接口。
WAI 不打算成为一个高级接口。它有两个明确的目标:通用性和性能。通过保持通用性,WAI 能够支持从独立服务器到旧式 CGI 的所有内容的后端,甚至直接与 Webkit 合作以生成伪桌面应用程序。性能方面将向我们介绍 Haskell 的许多酷炫功能。
Haskell 最大的优势之一——也是我们在 Yesod 中利用最多的东西之一——是强静态类型。在我们开始编写如何解决某事的代码之前,我们需要考虑数据将是什么样子。WAI 就是这种范式的完美例子。我们想要表达的核心概念是应用程序的概念。应用程序最基本的表达形式是一个函数,它接受一个请求并返回一个响应。在 Haskell 行话中
type Application = Request -> Response
这只会引发一个问题:Request 和 Response 看起来像什么?请求包含许多信息,但最基本的信息是请求路径、查询字符串、请求头和请求体。响应只有三个部分:状态码、响应头和响应体。
我们如何表示像查询字符串这样的东西?Haskell 在二进制数据和文本数据之间严格分离。前者用 ByteString 表示,后者用 Text 表示。两者都是高度优化的数据类型,提供了一个高级、安全的 API。在查询字符串的情况下,我们将通过网络传输的原始字节存储为 ByteString,将解析后的解码值存储为 Text。
ByteString 表示单个内存缓冲区。如果我们天真地使用普通的 ByteString 来保存整个请求或响应体,我们的应用程序将永远无法扩展到大型请求或响应。相反,我们使用一种叫做枚举器的技术,其概念与 Python 中的生成器非常相似。我们的 Application 成为代表传入请求体的 ByteString 流的消费者,以及用于响应的单独流的生产者。
现在我们需要稍微修改一下 Application 的定义。Application 将接受一个 Request 值,其中包含头、查询字符串等,并将消费 ByteString 流,生成 Response。因此,Application 的修改后的定义是
type Application = Request -> Iteratee ByteString IO Response
IO 只是解释了应用程序可以执行哪些类型的副作用。在 IO 的情况下,它可以执行任何类型的与外部世界的交互,这对绝大多数 Web 应用程序来说都是一个明显的必要条件。
我们工具库中的技巧是我们如何生成响应缓冲区。我们在这里有两个相互竞争的愿望:最小化系统调用,以及最小化缓冲区复制。一方面,我们希望最小化发送数据到套接字的系统调用。要做到这一点,我们需要将传出数据存储在缓冲区中。但是,如果我们使这个缓冲区太大,我们将耗尽内存并减慢应用程序的响应时间。另一方面,我们希望最小化数据在缓冲区之间复制的次数,最好只从源缓冲区复制一次到目标缓冲区。
Haskell 的解决方案是生成器。生成器是关于如何填充内存缓冲区的指令,例如:将五个字节“hello”放置在下一个空闲位置。我们不是将内存缓冲区流传递给服务器,而是将这些指令流传递给 WAI 应用程序。服务器接收流并使用它来以最佳大小填充内存缓冲区。当每个缓冲区被填充时,服务器会进行系统调用来将数据发送到网络,然后开始填充下一个缓冲区。
(缓冲区的最佳大小将取决于许多因素,例如缓存大小。底层的 blaze-builder 库经过了大量的性能测试,以确定最佳的权衡。)
从理论上讲,这种优化可以在应用程序本身中执行。但是,通过将这种方法编码到接口中,我们能够简单地将响应头添加到响应体之前。结果是,对于中小型响应,整个响应可以使用单个系统调用发送,并且内存只复制一次。
现在我们有了应用程序,我们需要一种方法来运行它。在 WAI 行话中,这叫做处理程序。WAI 有一些基本的、标准的处理程序,例如独立服务器 Warp(下面会讨论)、FastCGI、SCGI 和 CGI。这种范围允许 WAI 应用程序在从专用服务器到共享主机的一切东西上运行。但除了这些之外,WAI 还有一些更有趣的后端
大多数开发人员可能都会使用 Warp。它足够轻量级,可以用于测试。它不需要配置文件、文件夹层次结构或长时间运行的、管理员拥有的进程。它是一个简单的库,可以编译到您的应用程序中或通过 Haskell 解释器运行。Warp 是一款非常快的服务器,它可以防御各种攻击向量,例如 Slowloris 和无限头。Warp 可以成为您唯一需要的 Web 服务器,尽管它也很乐意位于反向 HTTP 代理之后。
PONG 基准测试测量了各种服务器对 4 字节响应体“PONG”的每秒请求数。在 图 22.2 中显示的图表中,Yesod 被测量为构建在 Warp 之上的框架。可以看到,Haskell 服务器(Warp、Happstack 和 Snap)领先于其他服务器。
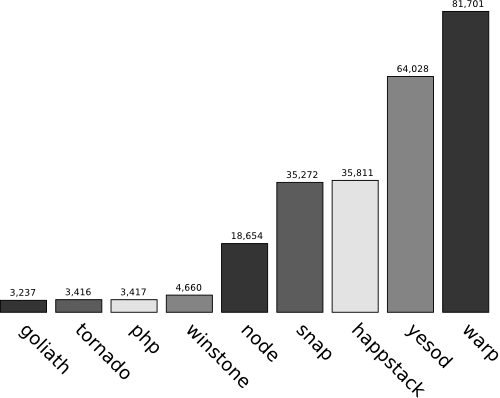
Warp 速度的绝大多数原因已经在 WAI 的总体描述中说明了:枚举器、生成器和打包数据类型。拼图中的最后一块来自 Glasgow Haskell Compiler(GHC)的多线程运行时。GHC 是 Haskell 的旗舰编译器,它拥有轻量级的绿色线程。与系统线程不同,可以启动数千个绿色线程,而不会对性能产生严重影响。因此,在 Warp 中,每个连接都由其自己的绿色线程处理。
下一个技巧是异步 I/O。任何希望扩展到每秒数万个请求的 Web 服务器都需要某种类型的异步通信。在大多数语言中,这涉及到使用回调进行复杂的编程。GHC 让我们作弊:我们可以像使用同步 API 一样进行编程,GHC 会自动在等待活动的不同绿色线程之间切换。
在表面之下,GHC 使用主机操作系统提供的任何系统,例如 kqueue、epoll 和 select。这让我们获得了基于事件的 I/O 系统的所有性能,而无需担心跨平台问题或以基于回调的方式编写代码。
在处理程序和应用程序之间,我们有中间件。从技术上讲,中间件是一种应用程序转换器:它接受一个应用程序,并返回一个新的应用程序。这被定义为
type Middleware = Application -> Application
理解中间件目的的最佳方法是查看一些常见的例子
gzip会自动压缩来自应用程序的响应。jsonp会在客户端提供回调参数时自动将 JSON 响应转换为 JSON-P 响应。autohead将根据应用程序的 GET 响应生成相应的 HEAD 响应。debug会将调试信息打印到控制台或每个请求的日志中。这里的想法是从应用程序中提取通用代码,并使其能够轻松共享。请注意,根据中间件的定义,我们可以轻松地将这些内容堆叠起来。中间件的一般工作流程是
在堆叠中间件的情况下,不是传递给应用程序或处理程序,而是中间的中间件实际上会分别传递给内部和外部中间件。
任何静态类型化都无法消除对测试的需求。我们都知道自动化测试对于任何严肃的应用程序来说都是必需的。wai-test是测试 WAI 应用程序的推荐方法。由于请求和响应是简单的数据类型,因此可以轻松地模拟一个假请求,将其传递给应用程序,并测试响应的属性。wai-test只是提供了一些便利函数来测试常见的属性,例如是否存在标题或状态码。
在典型的模型-视图-控制器 (MVC) 范式中,目标之一是将逻辑与视图分离。这种分离的部分是通过使用模板语言实现的。然而,解决这个问题有很多不同的方法。例如,在频谱的一端,PHP/ASP/JSP 允许你在模板中嵌入任何任意的代码。在另一端,你拥有像 StringTemplate 和 QuickSilver 这样的系统,它们被传递一些参数,并且没有其他方法与程序的其余部分进行交互。
每个系统都有其优缺点。拥有一个功能更强大的模板系统可以是一个巨大的便利。需要显示数据库表的内容吗?没问题,用模板拉入它。然而,这种方法很快会导致代码变得复杂,将数据库游标更新与 HTML 生成交织在一起。这通常可以在编写不当的 ASP 项目中看到。
虽然弱模板系统可以使代码变得简单,但它们也倾向于做很多重复的工作。你通常需要不仅保留原始值的数据类型,还要创建要传递给模板的值字典。维护这样的代码并不容易,而且通常编译器无法帮助你。
Yesod 的模板语言家族,莎士比亚语言,力求折衷。通过利用 Haskell 的标准引用透明性,我们可以确保我们的模板不会产生副作用。但是,它们仍然可以完全访问 Haskell 代码中可用的所有变量和函数。此外,由于它们在编译时经过了完整格式、变量解析和类型安全性的检查,因此打字错误不太可能让你在代码中搜索以查明错误。
为什么叫莎士比亚?
HTML 语言 Hamlet 是第一个编写的语言,最初基于 Haml 的语法。由于它当时是一个“简化”的 Haml,因此 Hamlet 似乎很合适。随着我们添加了 CSS 和 Javascript 选项,我们决定以 Cassius 和 Julius 来保持命名主题。在这一点上,Hamlet 看起来与 Haml 没有任何相似之处,但这个名字仍然保留了下来。
Yesod 中的一个总体主题是正确使用类型来让开发人员的生活更轻松。在 Yesod 模板中,我们有两个主要示例
Html类型。正如我们将在后面看到的,这会强制我们在必要时正确转义危险的 HTML,同时避免意外的双重转义。举一个现实世界的例子,假设用户通过表单向应用程序提交了他们的姓名。此数据将使用Text数据类型表示。现在,我们想将此变量(称为name)显示在一个页面中。类型系统(在编译时)会阻止它被简单地插入到 Hamlet 模板中,因为它不是Html类型。相反,我们必须以某种方式转换它。为此,有两个转换函数
toHtml会自动转义所有实体。因此,如果用户提交字符串<script src="http://example.com/evil.js"></script>,小于号将自动转换为<。preEscapedText会保留当前内容的准确性。因此,在来自可能不怀好意的用户的不可信输入的情况下,toHtml将是我们推荐的方法。另一方面,假设我们有一些存储在我们服务器上的静态 HTML,我们希望将其逐字插入到一些页面中。在这种情况下,我们可以将其加载到Text值中,然后应用preEscapedText,从而避免任何双重转义。
默认情况下,Hamlet 会在尝试插值的任何内容上使用toHtml函数。因此,只有当你想要避免转义时,才需要显式执行转换。这遵循了“宁可错杀,不可放过”的准则。
name <- runInputPost $ ireq textField "name"
snippet <- readFile "mysnippet.html"
return [hamlet|
<p>Welcome #{name}, you are on my site!
<div .copyright>#{preEscapedText snippet}
|]
类型安全 URL 的第一步是创建一个数据类型来表示站点中的所有路由。假设你有一个用于显示斐波那契数列的网站。该网站将为序列中的每个数字都有一个单独的页面,以及主页。这可以用 Haskell 数据类型建模
data FibRoute = Home | Fib Int
然后,我们可以创建一个这样的页面
<p>You are currently viewing number #{show index} in the sequence. Its value is #{fib index}.
<p>
<a href=@{Fib (index + 1)}>Next number
<p>
<a href=@{Home}>Homepage
然后,我们只需要一些函数将类型安全 URL 转换为字符串表示形式即可。在我们的案例中,它可能看起来像这样
render :: FibRoute -> Text render Home = "/home" render (Fib i) = "/fib/" ++ show i
幸运的是,定义和呈现类型安全 URL 数据类型的所有样板代码都由 Yesod 自动为开发人员处理。我们将在后面更深入地介绍它。
除了 Hamlet 之外,还有三种其他语言:Julius、Cassius 和 Lucius。Julius 用于 Javascript;但是,它是一种简单的直通语言,只允许插值。换句话说,除了意外使用插值语法外,任何一段 Javascript 都可以放到 Julius 中并保持有效。例如,为了测试 Julius 的性能,jQuery 在没有问题的情况下通过了该语言。
另外两种语言是替代的 CSS 语法。熟悉 Sass 和 Less 之间区别的人会立即认出这一点:Cassius 以空格分隔,而 Lucius 使用大括号。Lucius 事实上是 CSS 的超集,这意味着所有有效的 CSS 文件都是有效的 Lucius 文件。除了允许文本插值之外,还提供了一些辅助数据类型来建模单位大小和颜色。此外,类型安全 URL 在这些语言中也可以使用,这使得指定背景图像变得方便。
除了上面提到的类型安全性和编译时检查之外,专门用于 CSS 和 Javascript 的语言还为我们提供了其他一些优势
大多数 Web 应用程序都需要将信息存储在数据库中。传统上,这意味着某种 SQL 数据库。在这方面,Yesod 延续了悠久的传统,以 PostgreSQL 作为我们最常用的后端。但正如我们近年来所见,SQL 并不总是持久性问题的答案。因此,Yesod 的设计目的是能够很好地与 NoSQL 数据库配合使用,并且附带了 MongoDB 后端作为一等公民。
这种设计决策的结果是 Persistent,Yesod 的首选存储选项。Persistent 实际上有两个指导原则:使其尽可能地与后端无关,并让用户代码完全经过类型检查。
同时,我们完全认识到,不可能完全将用户屏蔽在后端的所有细节之外。因此,我们提供了两种类型的逃生路线
Persistent 中最基本的数据类型是PersistValue。它表示可以出现在数据库中的任何原始数据,例如数字、日期或字符串。当然,有时你会有一些更友好的数据类型需要存储,例如 HTML。为此,我们有PersistField类。在内部,PersistField通过PersistValue来表达自己。
所有这些都很棒,但我们希望将不同的字段组合在一起以形成更大的画面。为此,我们有PersistEntity,它基本上是PersistField的集合。最后,我们有PersistBackend,它描述了如何创建、读取、更新和删除这些实体。
作为一个实际的例子,考虑将一个人存储在数据库中。我们希望存储该人的姓名、生日和个人资料图片(PNG 文件)。我们创建一个新的实体Person,其中包含三个字段:Text、Day和PNG。每个字段都使用不同的PersistValue构造函数存储在数据库中:PersistText、PersistDay和PersistByteString,分别。
前两个映射没有令人惊讶的地方,但最后一个很有趣。没有专门的构造函数用于在数据库中存储 PNG 内容,因此我们使用了一种更通用的类型(ByteString,它只是一个字节序列)。我们可以使用相同的机制来存储其他类型的任意数据。
(通常认为的存储图像的最佳实践是将数据保存在文件系统中,并在数据库中保留指向图像的路径。我们并不反对使用这种方法,而是使用数据库存储的图像作为示例。)
所有这些如何在数据库中表示?以 SQL 为例:Person实体将变成一个包含三列的表(姓名、生日和图片)。每个字段都以不同的 SQL 类型存储:Text变成VARCHAR,Day变成Date,PNG变成BLOB(或BYTEA)。
MongoDB 的故事非常相似。Person 成为它自己的文档,它的三个字段分别成为 MongoDB 的字段。在 MongoDB 中,不需要数据类型或创建模式。
| 持久性 | SQL | MongoDB |
| PersistEntity | 表 | 文档 |
| PersistField | 列 | 字段 |
| PersistValue | 列类型 | 不适用 |
Persistent 在幕后处理所有数据编组问题。作为 Persistent 的用户,您可以完全忽略 Text 成为 VARCHAR 的事实。您可以简单地声明您的数据类型并使用它们。
与 Persistent 的每次交互都具有强类型。这可以防止您意外地将数字放入日期字段中;编译器将不接受它。此时,整个类别微妙的错误会消失。
在重构中,强类型的力量最为明显。假设您一直将用户的年龄存储在数据库中,并且您意识到您实际上想存储生日。您可以对实体声明文件进行单行更改,点击编译,并自动查找需要更新的每一行代码。
在大多数动态类型语言及其 Web 框架中,解决此问题的推荐方法是编写单元测试。如果您拥有完整的测试覆盖率,那么运行您的测试将立即揭示哪些代码需要更新。这很好,但它比真正的类型更弱的解决方案。
创建适用于多个 SQL 引擎的 SQL 模式可能很棘手。如何创建也适用于非 SQL 数据库(如 MongoDB)的模式?
Persistent 允许您以高级语法定义实体,并将自动为您创建 SQL 模式。在 MongoDB 的情况下,我们目前使用无模式方法。这也允许 Persistent 确保您的 Haskell 数据类型与数据库的定义完美匹配。
此外,拥有所有这些信息使 Persistent 能够为您自动执行更高级的功能,例如迁移。
Persistent 不仅根据需要创建模式文件,而且还会在可能的情况下自动应用数据库迁移。数据库修改是 SQL 标准中较不发达的部分之一,因此每个引擎对该过程都有不同的看法。因此,每个 Persistent 后端都定义了自己的迁移规则集。在 PostgreSQL 中,它有一组丰富的 ALTER TABLE 规则,我们广泛使用它们。由于 SQLite 缺少大部分功能,我们只能创建临时表并复制行。MongoDB 的无模式方法意味着不需要迁移支持。
此功能是故意限制的,以防止任何数据丢失。它不会自动删除任何列;相反,它会给您一个错误消息,告诉您为了继续必须进行哪些不安全操作。然后,您可以选择手动运行它提供的 SQL,或更改数据模型以避免危险行为。
Persistent 本质上是非关系型的,这意味着它对后端支持关系没有要求。但是,在许多用例中,我们可能希望使用关系。在这些情况下,开发人员将能够完全访问它们。
假设我们现在想要存储每个用户的技能列表。如果我们正在编写一个特定于 MongoDB 的应用程序,我们可以直接将该列表存储为原始 Person 实体中的新字段。但是,这种方法在 SQL 中不起作用。在 SQL 中,我们称这种关系为一对多关系。
这样做的目的是将对“一”实体(人)的引用存储在每个“多”实体(技能)中。然后,如果我们想找到一个人拥有的所有技能,我们只需找到所有引用该人的技能。对于此引用,每个实体都有一个 ID。正如您可能现在所预料的那样,这些 ID 是完全类型安全的。Person ID 的数据类型为 PersonId。因此,要添加我们的新技能,我们只需将以下内容添加到我们的实体定义中
Skill
person PersonId
name Text
description Text
UniqueSkill person name
此 ID 数据类型概念贯穿 Persistent 和 Yesod。您可以根据 ID 派发。在这种情况下,Yesod 将自动将 ID 的文本表示形式编组到内部表示形式,并在过程中捕获任何解析错误。这些 ID 用于使用 get 和 delete 函数进行查找和删除,并由插入和查询函数 insert 和 selectList 返回。
如果我们正在查看典型的模型-视图-控制器 (MVC) 范式,Persistent 是模型,Shakespeare 是视图。这将使 Yesod 成为控制器。
Yesod 最基本的功能是路由。它具有声明性语法和类型安全分派。在此之上,Yesod 提供了许多其他功能:流式内容生成、小部件、i18n、静态文件、表单和身份验证。但 Yesod 添加的核心功能实际上是路由。
这种分层方法使用户更容易交换系统的不同组件。有些人对使用 Persistent 不感兴趣。对于他们来说,核心系统中没有任何内容提到 Persistent。同样,虽然它们是常用功能,但并非每个人都需要身份验证或静态文件服务。
另一方面,许多用户会希望集成所有这些功能。而且,在启用 Yesod 中可用的所有优化时这样做并不总是直截了当的。为了简化这个过程,Yesod 还提供了一个脚手架工具,用于使用最常用的功能设置一个基本站点。
鉴于路由实际上是 Yesod 的主要功能,让我们从那里开始。路由语法非常简单:资源模式、名称和请求方法。例如,一个简单的博客网站可能看起来像
/ HomepageR GET /add-entry AddEntryR GET POST /entry/#EntryId EntryR GET
第一行定义了主页。这表示“我响应域的根路径,我被称为 HomepageR,并且我回答 GET 请求。”(资源名称后面的“R”只是一个约定,它除了向开发人员提示某些东西是路由之外没有任何特殊含义。)
第二行定义了添加条目页面。这次,我们回答 GET 和 POST 请求。您可能想知道为什么 Yesod 与大多数框架不同,要求您明确声明您的请求方法。原因是 Yesod 尝试尽可能地遵循 RESTful 原则,而 GET 和 POST 请求实际上具有非常不同的含义。您不仅要分别声明这两个方法,而且稍后您还要分别定义它们的处理程序函数。(这实际上是 Yesod 中的一个可选功能。如果您愿意,您可以省略方法列表,您的处理程序函数将处理所有方法。)
第三行更有趣。在第二个斜杠之后,我们有 #EntryId。这定义了一个类型为 EntryId 的参数。我们已经在 Persistent 部分中提到了此功能:Yesod 现在将自动将路径组件编组到相关的 ID 值中。假设 SQL 后端(Mongo 稍后讨论),如果用户请求 /entry/5,处理程序函数将使用参数 EntryId 5 被调用。但是,如果用户请求 /entry/some-blog-post,Yesod 将返回 404。
这显然在大多数其他 Web 框架中也是可能的。例如,Django 采用的方法将使用正则表达式匹配路由,例如 r"/entry/(\d+)"。然而,Yesod 方法提供了一些优势
/calendar/#Day;您是否想在您的路由中键入匹配日期的正则表达式?Day 值。在 Django 等效项中,该函数将收到一段文本,然后它必须自行编组。这很乏味、重复且效率低下。#EntryId 仍然可以正常工作,类型系统将指示 Yesod 如何解析路由。在正则表达式系统中,您必须遍历所有路由并将 \d+ 更改为匹配 GUID 所需的任何正则表达式怪物。这种路由方法催生了 Yesod 最强大的功能之一:类型安全的 URL。您不是简单地拼接文本片段来引用路由,而是您的应用程序中的每个路由都可以用一个 Haskell 值来表示。这立即消除了大量 404 未找到错误:生成无效 URL 根本不可能。(仍然有可能生成会导致 404 错误的 URL,例如,通过引用不存在的博客文章。但是,所有 URL 都会被正确地形成。)
那么这种魔法是如何运作的?每个站点都有一个路由数据类型,每个资源模式都有自己的构造函数。在我们之前的示例中,我们将得到类似于以下内容:
data MySiteRoute = HomepageR
| AddEntryR
| EntryR EntryId
如果您想链接到主页,请使用 HomepageR。要链接到特定条目,请使用带有 EntryId 参数的 EntryR 构造函数。例如,要创建一个新条目并重定向到它,您可以编写
entryId <- insert (Entry "My Entry" "Some content") redirect RedirectTemporary (EntryR entryId)
Hamlet、Lucius 和 Julius 都包含对这些类型安全 URL 的内置支持。在 Hamlet 模板中,您可以轻松地创建指向添加条目页面的链接
<a href=@{AddEntryR}>Create a new entry.
最好的部分?就像 Persistent 实体一样,编译器会让您诚实。如果您更改了任何路由(例如,您想在条目路由中包含年份和月份),Yesod 将强制您更新整个代码库中的每一处引用。
定义路由后,您需要告诉 Yesod 您希望如何响应请求。这就是处理程序函数发挥作用的地方。设置很简单:对于每个资源(例如,HomepageR)和请求方法,创建一个名为 methodResourceR 的函数。在我们之前的示例中,我们需要四个函数:getHomepageR、getAddEntryR、postAddEntryR 和 getEntryR。
从路由中收集的所有参数都作为参数传递给处理程序函数。getEntryR 将采用类型为 EntryId 的第一个参数,而所有其他函数将不采用任何参数。
处理程序函数驻留在 Handler monad 中,它提供了许多功能,例如重定向、访问会话和运行数据库查询。对于最后一个,开始 getEntryR 函数的典型方法是
getEntryR entryId = do
entry <- runDB $ get404 entryId
这将运行一个数据库操作,从数据库中获取与给定 ID 关联的条目。如果没有这样的条目,它将返回 404 响应。
每个处理函数都会返回某个值,该值必须是HasReps的实例。这是另一个正在发挥作用的 RESTful 特性:与其只返回一些 HTML 或 JSON,您可以返回一个值,该值会根据 HTTP Accept 请求头返回其中之一。换句话说,在 Yesod 中,资源是特定的一块数据,并且可以以多种表示形式返回。
假设您想在网站的几个不同页面上包含一个导航栏。此导航栏将加载五个最新的博客文章(存储在您的数据库中),生成一些 HTML,然后需要一些 CSS 和 Javascript 来进行样式设置和增强。
如果没有一个更高级的接口将这些组件绑定在一起,这将很难实现。您可以将 CSS 添加到网站范围的 CSS 文件中,但这会添加一些您并不总是需要的额外声明。Javascript 也是如此,不过更糟糕的是:额外的 Javascript 可能会在非预期使用的页面上造成问题。您还将通过必须从多个处理函数生成数据库结果来破坏模块化。
在 Yesod 中,我们有一个非常简单的解决方案:小部件。小部件是一段代码,它将 HTML、CSS 和 Javascript 绑定在一起,允许您向头部和主体添加内容,并且可以运行任何属于处理程序的任意代码。例如,要实现我们的导航栏
-- Get last five blog posts. The "lift" says to run this code like we're in the handler.
entries <- lift $ runDB $ selectList [] [LimitTo 5, Desc EntryPosted]
toWidget [hamlet|
<ul .navbar>
$forall entry <- entries
<li>#{entryTitle entry}
|]
toWidget [lucius| .navbar { color: red } |]
toWidget [julius|alert("Some special Javascript to play with my navbar");|]
但这里还有更多功能。当您在 Yesod 中生成页面时,标准方法是将多个小部件组合成一个包含所有页面内容的单个小部件,然后应用defaultLayout。此函数是针对每个站点定义的,并应用标准的站点布局。
有两种开箱即用的方法来处理 CSS 和 Javascript 的位置
style和script标签中。link和script标签引用它们。第二点需要一些说明。小部件不仅包含原始 Javascript,还包含 Javascript 依赖项列表。例如,许多网站会引用 jQuery 库,然后添加一些使用它的 Javascript。Yesod 能够通过yepnope.js自动将所有这些转换为异步加载。
换句话说,小部件允许您创建模块化的、可组合的代码,这将导致非常高效地提供您的静态资源。
许多网站共享常见的功能区域。也许这两个最常见的例子是提供静态文件和身份验证。在 Yesod 中,您可以使用子站点轻松地添加此代码。您只需在路由中添加一行即可。例如,要添加静态子站点,您需要编写
/static StaticR Static getStatic
第一个参数告诉子站点在网站中的哪个位置开始。静态子站点通常用于/static,但您可以使用任何您想要的。StaticR是路由的名称;这也完全由您决定,但约定是使用StaticR。Static是静态子站点的名称;这是您无法控制的。getStatic是一个函数,它返回静态站点的设置,例如静态文件的位置。
与您所有的处理程序一样,子站点处理程序也可以访问defaultLayout函数。这意味着一个设计良好的子站点会自动使用您的站点皮肤,而无需您进行任何额外干预。
Yesod 一直是一个非常有意义的项目。它给了我一个机会在一个大型系统中与一群不同的开发人员一起工作。真正让我震惊的一件事是,最终产品与我最初的意图有多么不同。我最初是通过创建一个目标列表来开始 Yesod 的。我们目前在 Yesod 中宣传的许多主要功能都不在该列表中,并且该列表中很大一部分不再是我计划实现的东西。第一个教训是
您在开始工作后会对您需要的系统有更好的了解。不要把自己局限于最初的想法。
因为这是我第一段主要的 Haskell 代码,我在 Yesod 的开发过程中学到了很多关于这门语言的知识。我相信其他人也能理解“我怎么会写出这样的代码?”的感觉。即使最初的代码没有达到我们目前在 Yesod 中的代码的水平,它也足够扎实,足以启动该项目。第二个教训是
不要被所谓的缺乏对工具的掌握所阻碍。编写您所能写出的最好的代码,并不断改进它。
Yesod 开发中最困难的步骤之一是从单人团队——我——转变为与其他人合作。最初很简单,只是在 GitHub 上合并拉取请求,最终发展到拥有多位核心维护者。我建立了一些自己的开发模式,这些模式从未被解释或记录过。因此,贡献者发现很难提取我最新的未发布更改并进行试用。这阻碍了其他人进行贡献和测试。
当 Greg Weber 加入成为 Yesod 的另一位负责人时,他制定了许多非常缺乏的编码标准。为了加剧问题,在使用 Haskell 开发工具链时存在一些固有的困难;特别是在处理 Yesod 的大量软件包时。自那时起,整个 Yesod 团队的目标之一是创建标准脚本和工具来自动化构建。其中许多工具正在被重新引入通用 Haskell 社区。最后一条教训是
尽早考虑如何让其他人容易使用您的项目。