PyPy 是一个 Python 实现,也是一个动态语言实现框架。
本章假设读者熟悉一些基本的解释器和编译器概念,例如字节码和常量折叠。
Python 是一种高级动态编程语言。它由荷兰程序员 Guido van Rossum 于 20 世纪 80 年代后期发明。Guido 的原始实现是一个用 C 语言编写的传统字节码解释器,因此被称为 CPython。现在有许多其他的 Python 实现。其中最值得注意的是 Jython,它用 Java 编写,允许与 Java 代码交互;IronPython,它用 C# 编写,并与微软的 .NET 框架交互;以及 PyPy,本章的主题。CPython 仍然是最广泛使用的实现,并且目前是唯一支持 Python 3(下一代 Python 语言)的实现。本章将解释 PyPy 中的设计决策,这些决策使其有别于其他 Python 实现,甚至有别于任何其他动态语言实现。
除了极少数的 C 存根之外,PyPy 完全是用 Python 编写的。PyPy 源代码树包含两个主要组件:Python 解释器和 RPython 翻译工具链。Python 解释器是面向程序员的运行时,使用 PyPy 作为 Python 实现的人员会调用它。它实际上是用 Python 的一个子集编写的,称为受限 Python(通常缩写为 RPython)。用 RPython 编写 Python 解释器的目的是为了将解释器提供给 PyPy 的第二个主要部分,即 RPython 翻译工具链。RPython 翻译器接收 RPython 代码并将其转换为选定的低级语言,最常见的是 C。这使得 PyPy 成为一个自托管实现,这意味着它是用它所实现的语言编写的。正如我们将在本章中看到的那样,RPython 翻译器也使 PyPy 成为一个通用的动态语言实现框架。
PyPy 强大的抽象使其成为最灵活的 Python 实现。它具有近 200 个配置选项,这些选项从选择不同的垃圾回收器实现到更改各种翻译优化的参数不等。
由于 RPython 是 Python 的一个严格子集,因此 PyPy Python 解释器可以在另一个未经翻译的 Python 实现之上运行。当然,这非常慢,但它使得能够快速测试解释器中的更改。它还允许使用普通的 Python 调试工具来调试解释器。PyPy 的大多数解释器测试都可以在未经翻译的解释器和已翻译的解释器上运行。这允许在开发过程中进行快速测试,并确保已翻译的解释器与未经翻译的解释器行为相同。
在大多数情况下,PyPy Python 解释器的细节与 CPython 的细节非常相似;PyPy 和 CPython 在解释过程中使用几乎相同的字节码和数据结构。两者之间主要的区别在于 PyPy 有一个巧妙的抽象,称为“对象空间”(简称 objspaces)。一个 objspace 封装了表示和操作 Python 数据类型所需的所有知识。例如,对两个 Python 对象执行二元运算或获取对象的属性完全由 objspace 处理。这使解释器无需了解 Python 对象的实现细节。字节码解释器将 Python 对象视为黑盒,并在需要操作它们时调用 objspace 方法。例如,以下是 BINARY_ADD 操作码的粗略实现,当两个对象用 + 运算符组合时会调用该操作码。请注意,操作数没有被解释器检查;所有处理都立即委托给 objspace。
def BINARY_ADD(space, frame):
object1 = frame.pop() # pop left operand off stack
object2 = frame.pop() # pop right operand off stack
result = space.add(object1, object2) # perform operation
frame.push(result) # record result on stack
objspace 抽象具有许多优点。它允许在不修改解释器的情况下交换新的数据类型实现。此外,由于操作对象的唯一方法是通过 objspace,因此 objspace 可以拦截、代理或记录对对象的运算。利用 objspace 的强大抽象,PyPy 已经尝试过“thunk”,其中结果可以按需延迟但完全透明地计算,以及“tainting”,其中对对象的任何操作都会引发异常(用于通过不受信任的代码传递敏感数据)。然而,objspace 最重要的应用将在第 19.4 节中讨论。
在普通 PyPy 解释器中使用的 objspace 称为“标准 objspace”(简称 std objspace)。除了 objspace 系统提供的抽象之外,标准 objspace 还提供了另一层间接性;单个数据类型可以有多个实现。然后使用多方法分派对数据类型进行操作。这允许为给定的数据选择最有效的表示形式。例如,Python 长整型(表面上是大整数数据类型)可以在它足够小的时候表示为标准机器字长整数。只有在必要时才需要使用内存和计算上更昂贵的任意精度长整型实现。甚至还有一个使用标记指针实现的 Python 整数实现。容器类型也可以专门用于某些数据类型。例如,PyPy 有一个针对字符串键优化的字典(Python 的哈希表数据类型)实现。相同数据类型可以由不同的实现表示的事实对于应用程序级代码是完全透明的;针对字符串优化的字典与通用字典相同,如果其中放入非字符串键,它将优雅地退化。
PyPy 区分解释器级(interp-level)和应用程序级(app-level)代码。解释器级代码(大多数解释器都是用它编写的)必须是 RPython,并且会被翻译。它直接使用 objspace 和包装的 Python 对象。应用程序级代码始终由 PyPy 字节码解释器运行。与 C 或 Java 相比,尽管解释器级 RPython 代码很简单,但 PyPy 开发人员发现,对于解释器的某些部分,最容易使用纯应用程序级代码。因此,PyPy 支持在解释器中嵌入应用程序级代码。例如,Python print 语句的功能(将对象写入标准输出)是用应用程序级 Python 实现的。内置模块也可以部分用解释器级代码编写,部分用应用程序级代码编写。
RPython 翻译器是一个由多个降低阶段组成的工具链,这些阶段将 RPython 重写为目标语言,通常是 C。翻译的较高阶段如图 19.1所示。翻译器本身是用(不受限制的)Python 编写的,并且与 PyPy Python 解释器紧密相关,原因将在稍后阐明。
翻译器首先要做的是将 RPython 程序加载到其进程中。(这是使用普通的 Python 模块加载支持完成的。)RPython 对普通的动态 Python 施加了一套限制。例如,函数不能在运行时创建,并且单个变量不能有容纳不兼容类型的可能性,例如整数和对象实例。但是,当程序最初由翻译器加载时,它是在普通的 Python 解释器上运行的,并且可以使用 Python 的所有动态特性。PyPy 的 Python 解释器(一个巨大的 RPython 程序)大量使用了此特性进行元编程。例如,它为标准 objspace 多方法分派生成代码。唯一的要求是,在翻译器开始翻译的下一阶段之前,程序必须是有效的 RPython。
翻译器通过一个称为“抽象解释”的过程构建 RPython 程序的流程图。抽象解释重用 PyPy Python 解释器来解释具有特殊 objspace(称为“流程 objspace”)的 RPython 程序。回想一下,Python 解释器将程序中的对象视为黑盒,调用 objspace 来执行任何操作。流程 objspace 只有两个对象,而不是标准的 Python 对象集:变量和常量。变量表示在翻译期间未知的值,而常量(毫不奇怪)表示已知的不变值。流程 objspace 具有常量折叠的基本功能;如果它被要求执行所有参数都是常量的操作,它将静态地对其进行评估。在 RPython 中,什么是不可变的以及必须是常量的,其范围比标准 Python 中的要广。例如,模块在 Python 中是绝对可变的,但在流程 objspace 中是常量,因为它们在 RPython 中不存在,并且必须由流程 objspace 常量折叠。当 Python 解释器解释 RPython 函数的字节码时,流程 objspace 会记录它被要求执行的操作。它会小心地记录条件控制流构造的所有分支。抽象解释函数的最终结果是一个流程图,该流程图由链接的块组成,其中每个块都具有一个或多个操作。
需要一个流程图生成过程的示例。考虑一个简单的阶乘函数
def factorial(n):
if n == 1:
return 1
return n * factorial(n - 1)
该函数的流程图如下所示
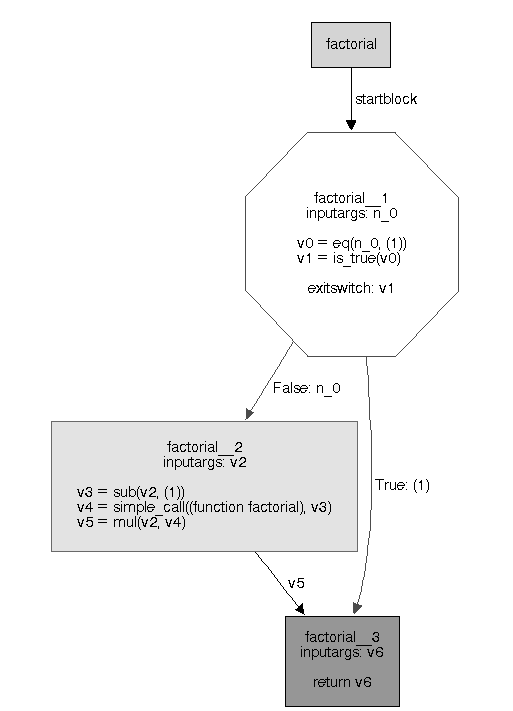
阶乘函数已被划分为包含流程空间记录的操作的块。每个块都有输入参数和对变量和常量进行操作的操作列表。第一个块在末尾有一个退出开关,该开关确定在第一个块运行后控制流将传递到哪个块。退出开关可以基于某个变量的值或最后一个操作中是否发生异常。控制流遵循块之间的线条。
在流程 objspace 中生成的流程图采用静态单赋值形式或 SSA,这是一种编译器中常用的中间表示。SSA 的关键特性是每个变量只赋值一次。此属性简化了许多编译器转换和优化的实现。
生成函数图后,注释阶段开始。注释器为每个操作的结果和参数分配一个类型。例如,上面的阶乘函数将被注释为接受并返回一个整数。
下一阶段称为 RTyping。RTyping 使用注释器中的类型信息将每个高级流程图操作扩展为低级操作。这是翻译中目标后端起作用的第一部分。后端为 RTyper 选择一个类型系统以将程序专门化。RTyper 目前有两个类型系统:一个用于 C 等后端的低级类型系统和一个用于具有类的更高级别类型系统的类型系统。高级 Python 操作和类型被转换为类型系统的级别。例如,操作数被注释为整数的 add 操作将生成具有低级类型系统的 int_add 操作。更复杂的操作(如哈希表查找)会生成函数调用。
在 RTyping 之后,会对低级流程图进行一些优化。它们大多是传统的编译器种类,例如常量折叠、存储下沉和死代码消除。
Python 代码通常会频繁进行动态内存分配。作为 Python 派生类的 RPython 继承了这种分配密集型模式。但是,在许多情况下,分配是临时的并且特定于函数的。“Malloc 移除”是一种解决这些情况的优化。Malloc 移除通过在可能的情况下将先前动态分配的对象“展平”为组件标量来移除这些分配。
要了解 malloc 移除的工作原理,请考虑以下函数,该函数以一种迂回的方式计算平面上的两点之间的欧几里得距离
def distance(x1, y1, x2, y2):
p1 = (x1, y1)
p2 = (x2, y2)
return math.hypot(p1[0] - p2[0], p1[1] - p2[1])
在最初的 RTyped 中,函数的主体具有以下操作
v60 = malloc((GcStruct tuple2))
v61 = setfield(v60, ('item0'), x1_1)
v62 = setfield(v60, ('item1'), y1_1)
v63 = malloc((GcStruct tuple2))
v64 = setfield(v63, ('item0'), x2_1)
v65 = setfield(v63, ('item1'), y2_1)
v66 = getfield(v60, ('item0'))
v67 = getfield(v63, ('item0'))
v68 = int_sub(v66, v67)
v69 = getfield(v60, ('item1'))
v70 = getfield(v63, ('item1'))
v71 = int_sub(v69, v70)
v72 = cast_int_to_float(v68)
v73 = cast_int_to_float(v71)
v74 = direct_call(math_hypot, v72, v73)
此代码在几个方面都不理想。分配了两个从不离开函数的元组。此外,访问元组字段存在不必要的间接寻址。
运行 malloc 移除会生成以下简洁的代码
v53 = int_sub(x1_0, x2_0) v56 = int_sub(y1_0, y2_0) v57 = cast_int_to_float(v53) v58 = cast_int_to_float(v56) v59 = direct_call(math_hypot, v57, v58)
元组分配已被完全移除,间接寻址也被扁平化。稍后,我们将看到如何在 PyPy JIT 中对应用程序级 Python 使用类似于 malloc 移除的技术(第 19.5 节)。
PyPy 还进行函数内联。与低级语言一样,内联提高了 RPython 的性能。令人惊讶的是,它还减小了最终二进制文件的大小。这是因为它允许进行更多的常量折叠和 malloc 移除,从而减少了整体代码大小。
现在处于优化后的低级流程图中的程序将传递给后端以生成源代码。在生成 C 代码之前,C 后端必须执行一些额外的转换。其中之一是异常转换,其中异常处理被重写为使用手动栈展开。另一个是插入栈深度检查。如果递归过深,这些检查会在运行时引发异常。通过计算程序调用图中的循环可以找到需要栈深度检查的位置。
C 后端执行的另一个转换是添加垃圾回收 (GC)。RPython 与 Python 一样,是一种垃圾回收语言,但 C 不是,因此必须添加垃圾回收器。为此,垃圾回收转换器将程序的流程图转换为垃圾回收程序。PyPy 的 GC 转换器很好地展示了翻译如何抽象化掉平凡的细节。在使用引用计数的 CPython 中,解释器的 C 代码必须仔细跟踪它正在操作的 Python 对象的引用。这不仅在整个代码库中硬编码了垃圾回收方案,而且容易出现细微的人为错误。PyPy 的 GC 转换器解决了这两个问题;它允许无缝地交换不同的垃圾回收方案。评估垃圾回收器实现(PyPy 有很多)非常简单,只需在翻译时调整配置选项即可。除了转换器错误之外,GC 转换器也不会犯引用错误或忘记在对象不再使用时通知 GC。GC 抽象的功能允许实现实际上不可能在解释器中硬编码的 GC 实现。例如,PyPy 的几个 GC 实现需要一个写入屏障。写入屏障是在每次将 GC 管理的对象放置到另一个 GC 管理的数组或结构中时必须执行的检查。如果手动插入写入屏障,过程将非常繁琐且容易出错,但如果由 GC 转换器自动执行,则非常简单。
C 后端终于可以发出 C 源代码了。生成的 C 代码是从低级流程图生成的,是一堆杂乱无章的 goto 和难以理解的变量名。编写 C 代码的一个优势在于,C 编译器可以完成大部分复杂的静态转换工作,以生成最终的二进制文件,例如循环优化和寄存器分配。
Python 与大多数动态语言一样,传统上以牺牲效率为代价换取灵活性。PyPy 的架构在灵活性和抽象性方面尤其丰富,这使得快速解释变得困难。std objspace 中强大的 objspace 和多方法抽象并非没有代价。因此,普通 PyPy 解释器的性能比 CPython 慢 4 倍。为了解决这个问题以及 Python 作为一种缓慢语言的声誉,PyPy 具有一个即时编译器(通常称为 JIT)。JIT 在程序运行时将常用代码路径编译成汇编语言。
PyPy JIT 利用了第 19.4 节中描述的 PyPy 独有的翻译架构。PyPy 实际上没有特定于 Python 的 JIT;它有一个 JIT 生成器。JIT 生成只是作为翻译期间的另一个可选过程实现的。希望进行 JIT 生成的解释器只需要进行两个特殊的函数调用,称为JIT 提示。
PyPy 的 JIT 是一个跟踪 JIT。这意味着它检测“热点”(即频繁运行)循环以通过编译成汇编语言来进行优化。当 JIT 决定要编译一个循环时,它会记录循环一次迭代中的操作,这个过程称为跟踪。这些操作随后被编译成机器代码。
如上所述,JIT 生成器在解释器中只需要两个提示即可生成 JIT:merge_point 和 can_enter_jit。can_enter_jit 告诉 JIT 解释器中的循环从哪里开始。在 Python 解释器中,这是 JUMP_ABSOLUTE 字节码的末尾。(JUMP_ABSOLUTE 使解释器跳转到应用程序级循环的头部。)merge_point 告诉 JIT 在哪里可以安全地从 JIT 返回到解释器。这是 Python 解释器中字节码调度循环的开头。
JIT 生成器在翻译的 RTyping 阶段之后被调用。回想一下,此时,程序的流程图由几乎准备好进行目标代码生成的低级操作组成。JIT 生成器在解释器中定位上述提示,并将其替换为在运行时调用 JIT 的调用。然后,JIT 生成器写入每个解释器希望进行 JIT 处理的函数的流程图的序列化表示。这些序列化流程图称为 jitcodes。整个解释器现在都用低级 RPython 操作来描述。jitcodes 被保存在最终的二进制文件中,以便在运行时使用。
在运行时,JIT 为程序中执行的每个循环维护一个计数器。当循环的计数器超过可配置的阈值时,JIT 被调用并开始跟踪。跟踪中的关键对象是元解释器。元解释器执行在翻译中创建的 jitcodes。因此,它正在解释主解释器,因此得名。当它跟踪循环时,它会创建一个正在执行的操作列表,并将其记录在 JIT 中间表示 (IR) 中,这是一种其他的操作格式。此列表称为循环的跟踪。当元解释器遇到对 jitted 函数(存在 jitcode 的函数)的调用时,元解释器会进入该函数并将其操作记录到原始跟踪中。因此,跟踪具有扁平化调用栈的效果;跟踪中唯一的调用是对 jit 不了解的解释器函数的调用。
元解释器被迫将跟踪专门化到它正在跟踪的循环迭代的属性。例如,当元解释器在 jitcode 中遇到条件时,它自然必须根据程序的状态选择一条路径。当它根据运行时信息做出选择时,元解释器会记录一个称为保护的 IR 操作。对于条件,这将是在条件变量上的 guard_true 或 guard_false 操作。大多数算术运算也具有保护,以确保运算没有溢出。本质上,保护对元解释器在跟踪时做出的假设进行了编码。当生成汇编代码时,保护将防止汇编代码在它未专门化的上下文中运行。当元解释器到达与开始跟踪时相同的 can_enter_jit 操作时,跟踪结束。循环 IR 现在可以传递给优化器。
JIT 优化器具有一些经典的编译器优化和许多针对动态语言的专门优化。后者中最重要的包括虚拟和可虚拟化。
虚拟是指已知不会逃逸跟踪的对象,这意味着它们不会作为参数传递给外部的、非 jitted 函数调用。结构和常量长度数组可以是虚拟的。虚拟不需要分配,它们的数据可以直接存储在寄存器和栈中。(这与关于翻译后端优化的章节中描述的静态 malloc 移除阶段非常相似。)虚拟优化消除了 Python 解释器中的间接寻址和内存分配效率低下问题。例如,通过成为虚拟,盒装 Python 整数对象会被取消装箱成简单的字大小整数,并且可以直接存储在机器寄存器中。
可虚拟化与虚拟非常相似,但可能会逃逸跟踪(即传递给非 jitted 函数)。在 Python 解释器中,保存变量值和指令指针的帧对象被标记为可虚拟化。这允许对帧进行栈操作和其他操作进行优化。尽管虚拟和可虚拟化相似,但在实现上它们没有任何共同之处。可虚拟化由元解释器在跟踪期间处理。这与在跟踪优化期间处理的虚拟不同。这样做的原因是可虚拟化需要特殊处理,因为它们可能会逃逸跟踪。具体来说,元解释器必须确保可能使用可虚拟化的非 jitted 函数实际上不会尝试获取其字段。这是因为在 jitted 代码中,可虚拟化的字段存储在栈和寄存器中,因此实际的可虚拟化可能与 jitted 代码中其当前值不一致。在 JIT 生成期间,访问可虚拟化的代码被重写为检查是否正在运行 jitted 汇编代码。如果是,则要求 JIT 从汇编代码中的数据更新字段。此外,当外部调用返回到 jitted 代码时,执行会回退到解释器。
优化完成后,跟踪就可以进行汇编了。由于 JIT IR 本身已经处于相当低的级别,因此汇编生成并不太困难。大多数 IR 操作仅对应于几个 x86 汇编操作。寄存器分配器是一个简单的线性算法。目前,在后端花费更多时间使用更复杂的寄存器分配算法以换取生成略好代码的做法还没有得到证明。汇编生成中最棘手的部分是垃圾回收集成和保护恢复。GC 必须知道生成的 JIT 代码中的栈根。这是通过 GC 中对动态根映射的特殊支持来实现的。
当保护失败时,已编译的汇编代码将不再有效,并且控制必须返回到字节码解释器。这种回退是 JIT 实现中最困难的部分之一,因为必须从保护失败时寄存器和栈的状态重建解释器状态。对于每个保护,汇编器都会写入一个紧凑的描述,说明重建解释器状态所需的所有值在哪里。在保护失败时,执行跳转到一个函数,该函数解码此描述并将恢复值传递给更高层以进行重建。失败的保护可能位于复杂操作码执行的中间,因此解释器不能只从下一个操作码开始。为了解决这个问题,PyPy 使用了一个黑洞解释器。黑洞解释器从保护失败点开始执行 jitcodes,直到到达下一个合并点。在那里,真正的解释器可以恢复。黑洞解释器之所以这样命名,是因为与元解释器不同,它不会记录它执行的任何操作。保护失败的过程如图19.3所示。
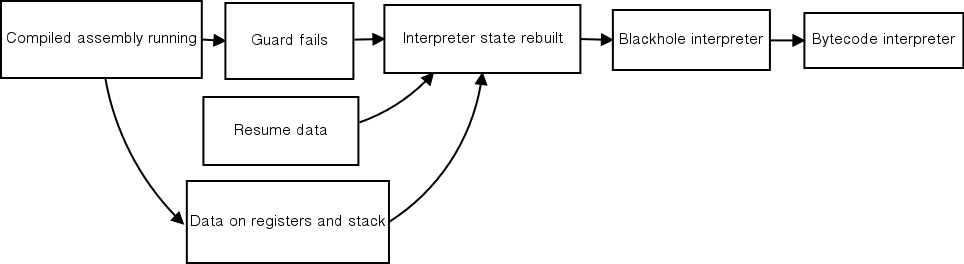
如前所述,对于任何条件频繁变化的循环,JIT 基本上都是无用的,因为保护失败会阻止汇编代码运行很多迭代。每个保护都有一个失败计数器。在失败计数超过某个阈值后,JIT 会从保护失败点开始跟踪,而不是回退到解释器。这个新的子跟踪称为桥接。当跟踪到达循环末尾时,桥接会被优化和编译,并且原始循环在保护处被修补以跳转到新的桥接而不是失败代码。这样,具有动态条件的循环也可以进行 jit 处理。
PyPy JIT 中使用的技术取得了多大的成功?在撰写本文时,PyPy 在一套全面的基准测试中,平均速度比 CPython 快 5 倍。使用 JIT,应用程序级 Python 有可能比 interp 级代码更快。PyPy 开发人员最近遇到了一个很好的问题,即必须为了性能而在应用程序级 Python 中编写 interp 级循环。
最重要的是,JIT 不特定于 Python 的事实意味着它可以应用于在 PyPy 框架内编写的任何解释器。这不必一定是语言解释器。例如,JIT 用于 Python 的正则表达式引擎。NumPy 是 Python 中用于数值计算和科学研究的强大的数组模块。PyPy 具有 NumPy 的实验性重新实现。它利用 PyPy JIT 的强大功能来加速数组上的操作。虽然 NumPy 实现仍处于早期阶段,但初步性能结果看起来很有希望。
虽然它在任何时候都胜过 C,但用 RPython 编写可能是一次令人沮丧的体验。最初很难适应它的隐式类型。并非所有 Python 语言特性都受支持,其他特性则受到任意限制。RPython 在任何地方都没有正式指定,并且翻译器接受的内容可能每天都会变化,因为 RPython 适应了 PyPy 的需求。本章的作者经常设法创建在翻译器中运行半个小时的程序,结果却以一个模糊的错误失败。
RPython 翻译器是一个全程序分析器的事实造成了一些实际问题。翻译代码中的任何最小更改都需要重新翻译整个解释器。这目前在快速、现代的系统上大约需要 40 分钟。这种延迟对于测试更改如何影响 JIT 尤其令人恼火,因为衡量性能需要一个已翻译的解释器。在翻译时需要整个程序存在,这意味着包含 RPython 的模块不能单独构建和加载到核心解释器之外。
PyPy 中的抽象级别并不总是像理论上那样清晰。虽然从技术上讲,JIT 生成器应该能够仅根据上面提到的两个提示为一种语言生成一个优秀的 JIT,但现实情况是它在某些代码上的表现比其他代码更好。Python 解释器已经做了很多工作来使其更“适合 JIT”,包括更多 JIT 提示,甚至为 JIT 优化了新的数据结构。
PyPy 的多层结构可能使追踪错误变得非常繁琐。Python 解释器错误可能直接存在于解释器源代码中,也可能隐藏在 RPython 的语义和翻译工具链中的某个地方。尤其是在无法在未翻译的解释器上重现错误时,调试非常困难。它通常涉及在几乎无法阅读的生成的 C 源代码上运行 GDB。
将 Python 的受限子集甚至翻译成像 C 这样的更低级语言并非易事。在第 19.4 节中描述的降低过程并不是真正独立的。在整个翻译过程中,函数都被注释和 rtyped,并且注释器具有一些低级类型的知识。因此,RPython 翻译器是相互依赖的错综复杂的网络。翻译器在几个地方确实需要清理,但这样做既不容易也不有趣。
为了应对自身复杂性(参见第 19.6 节),PyPy 采用了若干所谓的“敏捷”开发方法。其中最重要的是测试驱动开发。所有新功能和错误修复都需要进行测试以验证其正确性。PyPy Python 解释器还针对 CPython 的回归测试套件运行。PyPy 的测试驱动程序 py.test 已被分离出来,现在用于许多其他项目。PyPy 还拥有一个持续集成系统,该系统在各种平台上运行测试套件并翻译解释器。每天都会生成所有平台的二进制文件,并运行基准测试套件。所有这些测试确保了各个组件的行为,无论在复杂架构中进行了什么更改。
PyPy 项目中存在着强烈的实验文化。鼓励开发人员在 Mercurial 存储库中创建分支。在那里,开发中的想法可以在不破坏主分支的情况下进行完善。分支并不总是成功的,有些会被放弃。不过,如果有什么不同的话,那就是 PyPy 开发人员非常顽强。最著名的是,当前的 PyPy JIT 是向 PyPy 添加 JIT 的第五次尝试!
PyPy 项目还以其可视化工具而自豪。第 19.4 节中的流程图就是一个例子。PyPy 还提供工具来显示垃圾回收器随时间的调用情况,并查看正则表达式的解析树。特别令人感兴趣的是 jitviewer,这是一个程序,它允许人们直观地剥离 JIT 函数的各层,从 Python 字节码到 JIT IR 到汇编。(jitviewer 如图 19.4所示。)可视化工具帮助开发人员了解 PyPy 的多层如何相互交互。

Python 解释器将 Python 对象视为黑盒,并将所有行为都留给 objspace 来定义。各个 objspace 可以为 Python 对象提供特殊的扩展行为。objspace 方法还支持翻译中使用的抽象解释技术。
RPython 翻译器允许将垃圾回收和异常处理等细节从语言解释器中抽象出来。它还通过使用不同的后端打开了在许多不同的运行时平台上运行 PyPy 的可能性。
翻译架构最重要的用途之一是 JIT 生成器。JIT 生成器的通用性允许添加新语言和子语言(如正则表达式)的 JIT。PyPy 是当今最快的 Python 实现,因为它拥有 JIT 生成器。
虽然 PyPy 的大部分开发工作都投入到了 Python 解释器中,但 PyPy 可以用于任何动态语言的实现。多年来,使用 PyPy 编写了 JavaScript、Prolog、Scheme 和 IO 的部分解释器。
最后,一些从 PyPy 项目中吸取的经验教训
重复重构通常是必要的过程。例如,最初设想翻译器的 C 后端能够处理高级流程图!经过多次迭代,才诞生了当前的多阶段翻译过程。
PyPy 最重要的教训是抽象的力量。在 PyPy 中,抽象分离了实现关注点。例如,RPython 的自动垃圾回收允许开发人员在处理解释器时不必担心内存管理。同时,抽象也需要付出一定的认知成本。处理翻译链需要在脑海中同时处理翻译的各个阶段。错误所在的层级也可能因抽象而变得模糊;抽象泄漏(其中交换本应可互换的低级组件会破坏高级代码)是一个长期存在的问题。重要的是要使用测试来验证系统的所有部分是否正常工作,这样一来,一个系统中的更改就不会破坏另一个系统。更具体地说,抽象可能会通过创建过多的间接寻址来降低程序速度。
(R)Python 作为实现语言的灵活性使得试验新的 Python 语言特性(甚至新的语言)变得很容易。由于其独特的架构,PyPy 将在 Python 和动态语言实现的未来发挥重要作用。