multipart/mixed 消息GNU Mailman 是用于管理邮件列表的免费软件。几乎所有编写或使用自由和开源软件的人都遇到过邮件列表。邮件列表可以是基于讨论的,也可以是基于公告的,两者之间有各种各样的变体。有时邮件列表会网关到 Usenet 上的新闻组或类似服务,例如 Gmane。邮件列表通常有存档,其中包含发布到邮件列表的所有消息的历史记录。
GNU Mailman 自 1990 年代初期就已存在,当时 John Viega 编写了第一个版本,目的是将粉丝与新生的 Dave Matthews Band 连接起来,他与 Dave Matthews Band 的成员在大学时代是朋友。这个早期版本在 1990 年代中期引起了 Python 社区的注意,当时 Python 宇宙的中心已经从荷兰的 CWI(科学研究机构)转移到美国弗吉尼亚州雷斯顿的 CNRI(国家研究计划公司)。在 CNRI,我们使用 Majordomo(一个基于 Perl 的邮件列表管理器)运行各种与 Python 相关的邮件列表。当然,对于 Python 世界来说,维护如此多的 Perl 代码是不合适的。更重要的是,由于其设计,我们发现为了满足我们的目的(例如添加最小的反垃圾邮件措施)而修改 Majordomo 太困难了。
Ken Manheimer 在早期 GNU Mailman 的许多工作中起着至关重要的作用,并且许多优秀的开发人员从那时起为 Mailman 做出了贡献。今天,Mark Sapiro 负责维护稳定的 2.1 分支,而本章的作者 Barry Warsaw 专注于新的 3.0 版本。
John 做出的许多原始架构决策一直保留在代码中,直到 Mailman 3 分支,并且仍然可以在稳定分支中看到。在接下来的部分中,我将描述 Mailman 1 和 2 中一些更具问题的设计决策,以及我们在 Mailman 3 中如何解决这些问题。
在早期的 Mailman 1 时代,我们遇到了很多消息丢失或错误导致消息反复传递的问题。这促使我们阐明了两个对 Mailman 持续成功的至关重要的首要原则。
在 Mailman 2 中,我们重新设计了消息处理系统,以确保这两个原则始终至关重要。该系统的一部分已经稳定了至少十年,并且是 Mailman 今天无处不在的关键原因之一。尽管我们在 Mailman 3 中对这个子系统进行了现代化改造,但其设计和实现基本上保持不变。
Mailman 中的核心数据结构之一是电子邮件消息,它由一个消息对象表示。系统中的许多接口、函数和方法都采用三个参数:邮件列表对象、消息对象和一个元数据字典,用于在消息通过系统处理时记录和传递状态。
multipart/mixed 消息表面上,电子邮件消息是一个简单的对象。它由一些冒号分隔的键值对组成,称为标题,后面跟着一个空行,将标题与消息主体分开。这种文本表示应该易于解析、生成、推理和操作,但实际上它很快就会变得相当复杂。有无数的 RFC 描述了可能出现的所有变化,例如处理复杂数据类型,如图像、音频等。电子邮件可以包含 ASCII 英文,或任何语言和字符集。电子邮件消息的基本结构已被其他协议(如 NNTP 和 HTTP)反复借用,但每个协议略有不同。我们在 Mailman 上的工作催生了几个库,专门用于处理这种格式(通常称为“RFC822”,以 1982 年的创始IETF 标准命名)。最初为 GNU Mailman 开发的电子邮件库已进入 Python 标准库,在那里继续开发以使其更加符合标准并更强大。
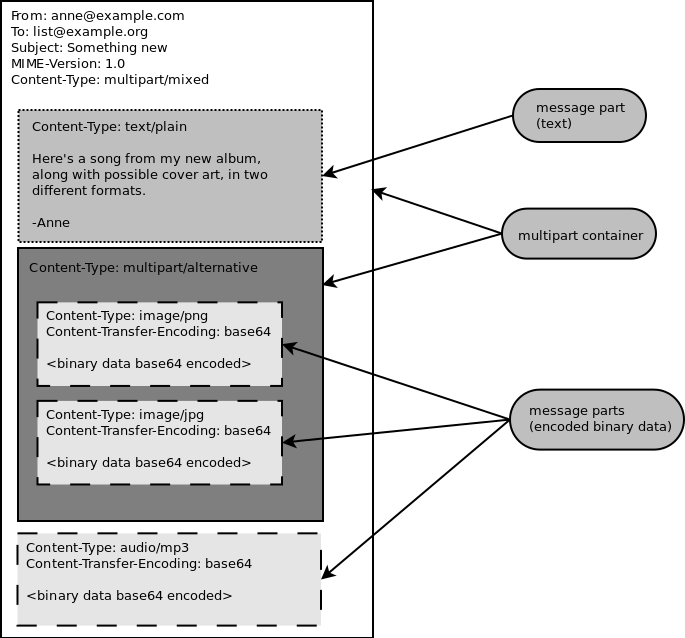
电子邮件消息可以充当其他类型数据的容器,如各种 MIME 标准中所定义。一个容器消息部分可以编码图像、音频或任何类型的二进制或文本数据,包括其他容器部分。在邮件阅读器应用程序中,这些被称为附件。 图 10.1 显示了一个复杂 MIME 消息的结构。实线边框的框是容器部分,虚线边框的框是 Base64 编码的二进制数据,点线边框的框是纯文本消息。
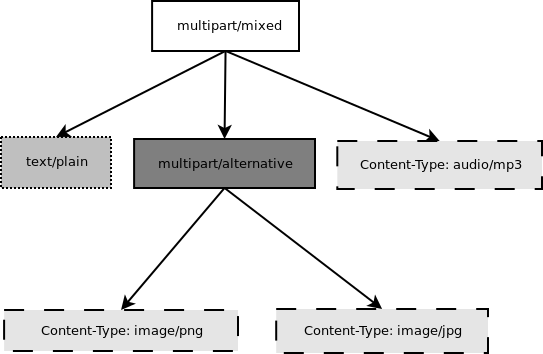
容器部分也可以任意嵌套;这些被称为多部分,实际上可以非常深。但任何电子邮件消息,无论其复杂程度如何,都可以建模为一棵树,树根是单个消息对象。在 Mailman 中,我们通常将其称为消息对象树,我们通过对根消息对象的引用来传递这棵树。 图 10.2 显示了图 10.1 中多部分消息的对象树。
Mailman 几乎总是会以某种方式修改原始消息。有时转换可以是相当良性的,例如添加或删除标题。有时我们会完全更改消息对象树的结构,例如当内容过滤器删除某些内容类型,如 HTML、图像或其他非文本部分时。Mailman 甚至可能折叠“multipart/alternatives”,其中一条消息以纯文本和富文本类型显示,或者添加包含有关邮件列表本身的额外部分。
Mailman 通常只解析消息的在线字节表示一次,即它第一次进入系统时。从那时起,它只处理消息对象树,直到准备好将其发送回传出邮件服务器。此时,Mailman 将树展平回字节表示形式。在此过程中,Mailman pickle) 消息对象树以快速存储到文件系统中,并从文件系统中重建。Pickles 是一种 Python 技术,用于将任何 Python 对象(包括其所有子对象)序列化为字节流,它非常适合优化电子邮件消息对象树的处理。Unpickling 是将此字节流反序列化回一个活动对象。通过将这些字节流存储在文件中,Python 程序获得了低成本的持久性。
邮件列表显然是 Mailman 系统中的另一个核心对象,Mailman 中的大多数操作都是以邮件列表为中心的,例如
等等。Mailman 中几乎所有操作都以邮件列表作为参数——它是如此基本。在 Mailman 3 中,邮件列表对象已经过彻底的重新设计,使其更加高效,并扩展了其灵活性。
John 最初的设计决策之一是如何在系统内部表示邮件列表对象。对于这种核心数据类型,他选择了具有多个基类的 Python 类,每个基类都实现了邮件列表责任的一小部分。这些协作基类,称为mixin 类,是一种巧妙的代码组织方式,使添加全新功能变得容易。通过嫁接一个新的 mixin 基类,核心 MailList 类可以轻松地适应新奇的东西。
例如,要向 Mailman 2 添加自动回复程序,将创建一个 mixin 类,该类保存特定于该功能的数据。当创建新的邮件列表时,数据会自动初始化。mixin 类还提供了支持自动回复功能所需的方法。这种结构在邮件 MailList 对象的持久性设计方面更加有用。
John 的另一个早期设计决策是使用 Python pickles 来存储 MailList 状态持久性。
在 Mailman 2 中,MailList 对象的状态存储在一个名为 config.pck 的文件中,该文件只是 MailList 对象字典的 pickle 表示形式。每个 Python 对象都有一个名为 __dict__ 的属性字典。因此,保存邮件列表对象只是将它的 __dict__ pickle 到一个文件中,加载它只需要从文件中读取 pickle 并重新构建它的 __dict__。
因此,当添加一个新的 mixin 类来实现一些新功能时,mixin 的所有属性都会自动 pickle 和 unpickle。我们唯一需要做的额外工作是维护一个模式版本号,以便在通过 mixin 添加新属性时自动升级旧的邮件列表对象,因为旧 MailList 对象的 pickle 表示将缺少新属性。
尽管这很方便,但 mixin 架构和 pickle 持久性最终都在自身的重压下崩溃了。网站管理员经常要求通过外部非 Python 系统访问邮件列表配置变量。但 pickle 协议完全特定于 Python,因此将所有有用的数据隔离在 pickle 中对他们来说是行不通的。此外,由于邮件列表的整个状态都包含在 config.pck 中,并且 Mailman 有多个进程需要读取、修改和写入邮件列表状态,我们不得不实现基于文件的排他锁和 NFS 安全锁以确保数据一致性。每次 Mailman 的某些部分想要更改邮件列表的状态时,它都必须获取锁,写入更改,然后释放锁。即使读取操作也可能需要重新加载列表的 config.pck 文件,因为其他进程可能在读取操作之前更改了它。这种对邮件列表操作的序列化证明非常缓慢且低效。
由于这些原因,Mailman 3 将所有数据存储在 SQL 数据库中。默认情况下使用 SQLite3,但很容易更改,因为 Mailman 3 使用称为 Storm 的对象关系映射器,它支持各种各样的数据库。PostgreSQL 支持只需几行代码即可添加,网站管理员可以通过更改一个配置变量来启用它。
另一个更大的问题是,在 Mailman 2 中,每个邮件列表都是一个孤岛。通常操作会跨越多个邮件列表,甚至所有邮件列表。例如,用户可能希望在休假时暂时暂停所有订阅。或者,网站管理员可能希望在系统中所有邮件列表的欢迎消息中添加免责声明。即使是弄清楚单个地址订阅了哪些邮件列表的简单问题也需要解开系统中每个邮件列表的状态,因为成员资格信息也保存在 config.pck 文件中。
另一个问题是每个config.pck文件都位于以邮件列表命名的目录中,但Mailman最初的设计并没有考虑虚拟域。这导致了一个非常不幸的问题,即两个邮件列表不能在不同的域中具有相同的名称。例如,如果你拥有example.com和example.org两个域名,并且希望它们独立运行,并允许在每个域名中创建不同的support邮件列表,那么在Mailman 2中,如果不修改代码,使用几乎不受支持的钩子,或使用传统的工作方法,强制在幕后使用不同的列表名称(这是像SourceForge这样的大型站点使用的方法),你将无法做到这一点。
Mailman 3通过改变邮件列表的识别方式以及将所有数据移入传统数据库解决了这个问题。邮件列表表的**主键**是**完全限定的列表名称**,或者如你所知,是发帖地址。因此,support@example.com和support@example.org现在是邮件列表表中完全独立的行,可以在单个Mailman系统中轻松共存。
消息通过一组称为**运行器**的独立进程在系统中流动。最初的概念是通过一种可预测的方式处理特定目录中发现的所有排队消息文件,现在有几个运行器只是独立的、长时间运行的进程,执行特定任务,并由一个主进程管理;稍后将详细介绍。当运行器管理目录中的文件时,它被称为**队列运行器**。
Mailman是严格的单线程程序,即使存在大量的并行性可供利用。例如,Mailman可以同时从邮件服务器接收消息,向接收者发送消息,处理退回邮件或存档消息。Mailman中的并行性是通过使用多个进程实现的,这些进程以运行器的形式存在。例如,有一个**传入**队列运行器,其唯一的任务是从上游邮件服务器接收(或拒绝)消息。有一个**传出**队列运行器,其唯一的任务是通过SMTP与上游邮件服务器通信,以便将消息发送到最终接收者。还有一个**归档器**队列运行器、**退回**处理队列运行器、用于将消息转发到NNTP服务器的队列运行器、用于编写摘要的运行器,以及其他几个运行器。不管理队列的运行器包括一个本地邮件传输协议服务器和一个管理HTTP服务器。
每个队列运行器负责一个单独的目录,即它的队列。虽然典型的Mailman系统可以使用每个队列一个进程来完美运行,但我们使用了一个巧妙的算法来允许在单个队列目录内进行并行处理,而无需任何类型的合作或锁定。秘诀在于我们命名队列目录中的文件的方式。
如上所述,每个流经系统的消息都伴随着一个元数据字典,该字典累积状态并允许Mailman的独立组件相互通信。Python的pickle库能够将多个对象序列化和反序列化到单个文件,因此我们可以将消息对象树和元数据字典都腌制到一个文件中。
Mailman的核心类叫做Switchboard,它提供了一个接口用于将消息对象树和元数据字典排队(即写入)和出队(即读取)到特定队列目录中的文件。每个队列目录至少有一个交换机实例,每个队列运行器实例正好有一个交换机。
腌制文件都以.pck后缀结尾,不过你可能还会在队列中看到.bak、.tmp和.psv文件。这些文件用于确保Mailman的两个神圣信条:任何文件都不应该丢失,任何消息都不应该被传送超过一次。但事情通常运作正常,这些文件可能非常少见。
如上所述,对于非常繁忙的站点,Mailman支持在每个队列目录中运行多个运行器进程,完全并行,并且无需它们之间进行通信或锁定来处理文件。它通过使用SHA1哈希命名腌制文件,然后允许单个队列运行器仅管理哈希空间的一部分来做到这一点。因此,如果一个站点想在退回队列上运行两个运行器,一个会处理来自哈希空间上半部分的文件,另一个会处理来自哈希空间下半部分的文件。哈希值是使用腌制的消息对象树的内容、消息的目标邮件列表的名称以及时间戳计算的。SHA1哈希值实际上是随机的,因此平均而言,一个有两个运行器的队列目录在每个进程中会有大约相同的工作量。并且因为哈希空间可以静态地划分,所以这些进程可以在同一个队列目录上运行,而无需任何干扰或通信。
这种算法有一个有趣的局限性。由于拆分算法将一个或多个哈希位分配给每个空间,因此每个队列目录的运行器数量必须是2的幂。这意味着每个队列可以有1、2、4或8个运行器进程,但不能有5个。实际上,这从来都不是问题,因为很少有站点需要超过4个进程来处理它们的负载。
这种算法还有另一个副作用,在该系统的早期设计阶段导致了一些问题。尽管电子邮件传递本身不可预测,但最佳的用户体验是通过FIFO顺序处理队列文件来提供的,这样对邮件列表的回复基本上按时间顺序发送出去。没有尽力尝试这样做会导致成员感到困惑。但是,使用SHA1哈希作为文件名会消除任何时间戳,并且出于性能原因,应该避免对队列文件进行stat()调用,或反腌制内容(例如,读取元数据中的时间戳)。
Mailman的解决方案是扩展文件名算法,在时间戳前缀中包含一个时间戳,表示自纪元以来的秒数(例如,<timestamp>+<sha1hash>.pck)。每个循环通过队列运行器都从执行os.listdir()开始,这会返回队列目录中的所有文件。然后,对于每个文件,它会拆分文件名,并忽略任何SHA1哈希不匹配其责任范围的文件名。然后,运行器根据文件名的时间戳部分对剩余文件进行排序。确实,对于多个队列运行器,每个运行器管理哈希空间的不同部分,这会导致并行运行器之间的排序问题,但实际上,时间戳排序足以保持最终用户对最佳努力顺序传递的感知。
实际上,这至少在过去十年中运行得非常好,只偶尔进行一些小的错误修复或扩展来处理模糊的边缘情况和故障模式。它是Mailman中最稳定的部分之一,从Mailman 2到Mailman 3基本上是完好无损地移植的。
有了所有这些运行器进程,Mailman需要一种简单的方法来一致地启动和停止它们;因此,主监视器进程诞生了。它必须能够处理队列运行器和不管理队列的运行器。例如,在Mailman 3中,我们通过LMTP接受来自传入上游邮件服务器的消息,LMTP是一种类似于SMTP的协议,但它只用于本地传递,因此可以简单得多,因为它不需要处理通过不可预测的互联网传递邮件的各种情况。LMTP运行器只是在一个端口上监听,等待上游邮件服务器连接并发送字节流。然后,它将这个字节流解析成一个消息对象树,创建一个初始元数据字典,并将它排队到一个处理队列目录中。
Mailman还有一个运行器,它监听另一个端口并处理HTTP上的REST请求。这个进程根本不处理队列文件。
一个典型的运行Mailman系统可能会有八到十个进程,它们都需要被适当且方便地停止和启动。它们也可能会偶尔崩溃;例如,当Mailman中的错误导致意外异常发生时。当这种情况发生时,正在传递的消息会被**转移**到一个保存区域,系统在异常发生时所处的状态会保存在消息元数据中。这确保了未捕获的异常不会导致消息被多次传递。理论上,Mailman站点管理员可以解决问题,然后**取消转移**有问题的消息以重新传递,从它停止的地方继续。在转移有问题的消息后,主进程会重新启动崩溃的队列运行器,该运行器开始处理其队列中剩余的消息。
当主监视器启动时,它会在配置文件中查找以确定要启动多少个和哪些类型的子运行器。对于LMTP和REST运行器,通常只有一个进程。对于队列运行器,如上所述,可以有2的幂个并行进程。主进程根据配置文件fork()和exec()所有运行器进程,将适当的命令行参数传递给每个进程(例如,告诉子进程查看哈希空间的哪一部分)。然后,主进程基本上会进入一个无限循环,阻塞直到它的一个子进程退出。它跟踪每个子进程的进程ID,以及子进程被重新启动的次数。这个计数可以防止灾难性的错误导致无法停止的重新启动级联。有一个配置变量指定允许多少次重新启动,在此之后,会记录错误,并且不会重新启动运行器。
当一个子进程退出时,主进程会查看退出代码和杀死子进程的信号。每个运行器进程都会安装一些信号处理程序,这些处理程序具有以下语义
SIGTERM: 有意停止子进程。它不会被重新启动。SIGTERM是init在改变运行级别时用来杀死进程的信号,也是Mailman本身用来停止子进程的信号。SIGINT: 也用于有意停止子进程,它是当在 shell 中使用 control-C 时发生的信号。运行器不会被重新启动。SIGHUP: 告诉进程关闭并重新打开它的日志文件,但继续运行。这用于轮转日志文件。SIGUSR1: 最初停止子进程,但允许主进程重新启动进程。这在 init 脚本的restart命令中使用。主进程也会响应所有这四个信号,但它除了将它们转发给所有子进程之外,不会做太多事情。因此,如果你向主进程发送SIGTERM,所有子进程都会收到SIGTERM并退出。主进程会知道子进程由于SIGTERM而退出,并且它会知道这是一个故意的停止,因此它不会重新启动运行器。
为了确保任何时候都只有一个主进程在运行,它会获取一个持续时间约为一天半的锁。主进程会安装一个SIGALRM处理程序,该处理程序每天唤醒一次主进程,以便它可以刷新锁。由于锁的持续时间比唤醒间隔长,因此在Mailman运行时,锁不应该超时或被破坏,除非系统崩溃或主进程被不可捕获的信号杀死。在这些情况下,主进程的命令行界面提供了一个选项来覆盖陈旧的锁。
这引出了主进程监视器故事的最后一部分,即它的命令行界面。实际的主脚本只需要很少的命令行选项。它和队列运行脚本都是有意保持简单。在Mailman 2中,主脚本相当复杂,并试图做太多的事情,这使得它更难理解和调试。在Mailman 3中,主进程的真正命令行界面位于bin/mailman脚本中,这是一种元脚本,包含许多子命令,类似于Subversion等程序流行的风格。这减少了需要安装在shell的PATH上的程序数量。bin/mailman有子命令用于启动、停止和重启主进程以及所有子进程,以及重新打开所有日志文件。start子命令会fork()并exec()主进程,而其他子命令只是向主进程发送适当的信号,主进程会将其传播到其子进程,如上所述。这种改进的责任分离使得理解每个单独的部分变得容易得多。
从邮件列表帖子首次接收开始,到它发送给列表成员,它会经历几个阶段。在Mailman 2中,每个处理步骤都由一个处理程序表示,一系列处理程序被组合成一个管道。因此,当一条消息进入系统时,Mailman会首先确定哪个管道将用于处理它,然后管道中的每个处理程序将依次被调用。一些处理程序会执行审核功能(例如,“这个人是否被允许发布到邮件列表?”),另一些会执行修改功能(例如,“我应该删除或添加哪些标题?”),还有一些会将消息复制到其他队列。后者的几个例子是
archiver队列,以便其队列运行程序将消息添加到归档中。outgoing队列,以便它可以被传递给上游邮件服务器,该服务器对传递给列表成员负最终责任。处理程序管道架构被证明非常强大。它提供了一种简单的方法,人们可以通过它扩展和修改Mailman来执行自定义操作。处理程序的接口相当简单,实现一个新的处理程序很简单,确保它被添加到正确管道中的正确位置以完成自定义操作。
这方面的一个问题是,在同一个管道中混合审核和修改会变得很麻烦。处理程序必须在管道中按顺序排列,否则会导致不可预测或不希望发生的事情。例如,如果添加RFC 2369 List-* 头部的处理程序出现在将消息复制到摘要整理器的处理程序之后,那么接收摘要的人就会收到列表帖子的不正确副本。在不同的情况下,在修改消息之前或之后审核它可能更有益。在Mailman 3中,审核和修改操作已被拆分为单独的子系统,以便更好地控制排序。
如前所述,LMTP运行程序将传入的字节流解析成一个消息对象树,并为消息创建一个初始元数据字典。然后,它将这些信息排队到一个或另一个队列目录。一些消息可能是电子邮件命令(例如,加入或离开邮件列表,获取自动帮助等),这些命令由单独的队列处理。大多数消息都是发布到邮件列表的,这些消息被放入incoming队列。incoming队列运行程序按顺序处理每个消息,通过一个由任意数量链接组成的链。大多数邮件列表使用一个内置链,但即使是这个链也是可以配置的。
图 10.3 说明了Mailman 3系统中的默认链集。链中的每个链接都由一个圆角矩形表示。内置链是在传入消息上应用初始审核规则的地方,在这个链中,每个链接都与一个规则相关联。规则只是代码片段,它们被传递三个典型参数:邮件列表、消息对象树和元数据字典。规则不应该修改消息;它们只是做出一个二元决策并返回一个布尔值,回答“规则匹配与否?”的问题。规则也可以在元数据字典中记录信息。
在图中,实线箭头表示规则匹配时的消息流,而虚线箭头表示规则不匹配时的消息流。每个规则的结果都会被记录在元数据字典中,以便稍后Mailman能够知道(并能够报告)哪些规则匹配了,哪些规则没有匹配。虚线箭头表示无条件发生的转换,无论规则是否匹配。
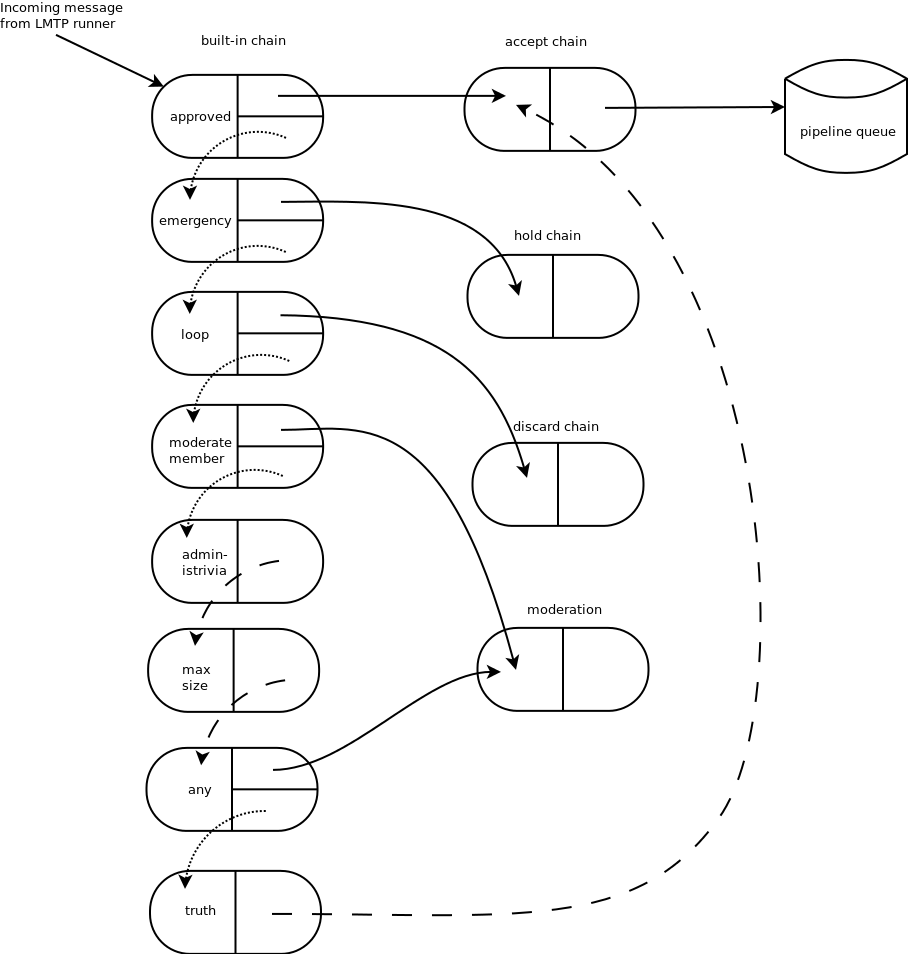
重要的是要注意,规则本身不会根据结果进行分派。在内置链中,每个链接都与一个操作相关联,该操作在规则匹配时执行。例如,当“loop”规则匹配时(这意味着邮件列表之前已经见过这条消息),该消息会立即被传递给“discard”链,该链会在进行一些簿记之后丢弃该消息。如果“loop”规则不匹配,链中的下一个链接将处理该消息。
在图 10.3中,与“administrivia”、“max-size”和“truth”规则相关的链接没有二元决策。对于前两个来说,这是因为它们的行动是延迟的,因此它们只是记录匹配结果,然后继续处理下一个链接。“any”规则然后在任何先前的规则匹配时匹配。这样,Mailman可以报告所有不允许发布消息的原因,而不仅仅是第一个原因。为了简单起见,这里还有几个类似的规则没有说明。
“truth”规则有点不同。它总是与链中的最后一个链接相关联,并且它总是匹配。结合倒数第二个“any”规则清除了所有先前匹配的消息,因此最后一个链接知道任何到达这里的消息都允许发布到邮件列表,因此它无条件地将消息移动到“accept”链。
这里没有描述链处理的一些其他细节,但架构非常灵活且可扩展,因此几乎可以实现任何类型的消息处理,站点可以自定义和扩展规则、链接和链。
消息到达“accept”链后会发生什么?该消息现在被认为适合该邮件列表,它被发送到pipeline队列,进行一些修改后,再传递给最终的接收者。这个过程将在下一节中详细介绍。
“hold”链将消息放入一个特殊的存储桶中,以便人工审核员进行审查。“moderation”链做了一些额外的处理,以决定是否应该接受消息、保留以供审核员批准、丢弃或拒绝。为了减少图中的混乱,没有说明用于将消息弹回原始发件人的“reject”链。
一旦一条消息通过链和规则并被接受发布,在它可以传递给最终接收者之前,它必须经过进一步处理。例如,一些标题可能会被添加或删除,一些消息可能会获得一些额外的装饰,提供重要的免责声明或信息,例如如何离开邮件列表。这些修改由一个包含一系列处理程序的管道执行。类似于链和规则,管道和处理程序是可扩展的,但有一些内置的管道用于常见情况。处理程序具有与规则类似的接口,接受邮件列表、消息对象和元数据字典。然而,与规则不同,处理程序可以并且会修改消息。图 10.4 说明了默认管道和处理程序集(为了简单起见,省略了一些处理程序)。
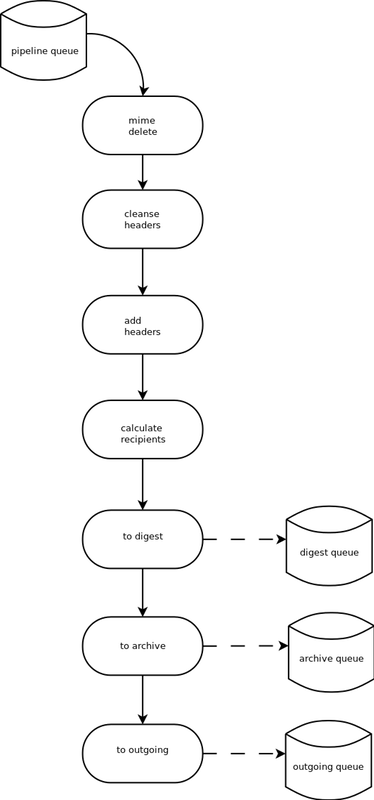
例如,已发布的消息需要添加一个Precedence:标题,它告诉其他自动化软件这条消息来自邮件列表。这个标题是一个事实上的标准,可以防止休假程序回复邮件列表。添加这个标题(以及其他标题修改)由“add headers”处理程序完成。与规则不同,处理程序的顺序通常无关紧要,消息总是流经管道中的所有处理程序。
一些处理程序将消息的副本发送到其他队列。如图 10.4所示,有一个处理程序为想要接收摘要的人制作消息的副本。副本还会被发送到归档队列,以便最终传递给邮件列表归档。最后,消息被复制到outgoing队列,以便最终传递给邮件列表的成员。
VERP 代表Variable Envelope Return Path,它是一种众所周知的技术,邮件列表使用它来明确地确定弹回的接收者地址。当邮件列表上的地址不再活动时,接收者的邮件服务器会将通知发送回发件人。对于邮件列表,你希望这个弹回回到邮件列表,而不是回到消息的原始作者;作者无法对弹回做任何事情,更糟糕的是,将弹回发送回作者可能会泄露有关谁订阅了邮件列表的信息。然而,当邮件列表收到弹回时,它可以做一些有用的事情,例如禁用弹回地址或将其从列表成员资格中删除。
这方面存在两个普遍的问题。首先,尽管这些弹回有一个标准格式(称为delivery status notifications,但许多已部署的邮件服务器不符合该标准。相反,它们的弹回消息的主体可能包含任意数量的难以用机器解析的乱码,这使得自动解析变得困难。事实上,Mailman使用一个库,该库包含数十个弹回格式启发式算法,所有这些启发式算法在Mailman存在的 15 年中都在现实世界中见过。
其次,想象一下这样一个情况,邮件列表的成员有多个转发地址。她可能用anne@example.com地址订阅了该列表,但该地址可能转发到person@example.org,而该地址可能再次将邮件转发到me@example.net。当example.net上的最终目标服务器收到邮件时,通常只会返回一个弹回邮件,说me@example.net地址无效。但发送邮件的Mailman服务器只知道该成员的anne@example.com地址,因此标记me@example.net的弹回邮件将不包含订阅地址,Mailman将忽略它。
VERP的出现利用了基本SMTP协议的要求,通过将此类弹回邮件返回给信封发件人来提供明确的弹回检测。这不是邮件正文中的From:字段,而是SMTP对话期间设置的MAIL FROM值。该值在整个传递路径中被保留,并且最终接收邮件服务器根据标准需要将弹回邮件发送到该地址。Mailman利用此功能将原始收件人电子邮件地址编码到MAIL FROM值中。
如果Mailman服务器是mylist@example.org,则发送到anne@example.com的邮件列表帖子的VERP编码信封发件人将是
mylist-bounce+anne=example.com@example.org
这里,+是本地地址分隔符,大多数现代邮件服务器都支持这种格式。因此,当弹回邮件返回时,它实际上将被发送到mylist-bounce@example.com,但To:标题仍将设置为VERP编码的收件人地址。然后,Mailman可以解析此To:标题以解码原始收件人anne@example.com。
虽然VERP是剔除邮件列表中无效地址的强大工具,但它也存在一个潜在的重要缺点。使用VERP要求Mailman为每个收件人发送一份邮件。如果没有VERP,Mailman可以将同一封邮件的副本打包发送给多个收件人,从而减少整体带宽和处理时间。但VERP要求每个收件人都有一个唯一的MAIL FROM,而唯一的方法是发送一份邮件。通常情况下,这是一个可以接受的折衷方案,实际上,一旦为VERP发送了这些个性化的邮件,Mailman还可以执行很多有用的操作。例如,它可以在消息的页脚中嵌入一个针对每个收件人定制的URL,为他们提供一个从列表中退订的直接链接。您甚至可以想象各种类型的邮件合并操作,以便为每个收件人定制邮件正文。
Mailman 3中的一项关键架构变更解决了多年来的一个常见请求:允许Mailman更轻松地与外部系统集成。2007年,当我被Ubuntu项目的公司赞助商Canonical聘用时,我的工作最初是为Launchpad添加邮件列表,Launchpad是一个用于软件项目的协作和托管平台。我知道Mailman 2可以完成这项工作,但有一个要求是使用Launchpad的网络用户界面而不是Mailman的默认用户界面。由于Launchpad邮件列表几乎总是讨论列表,所以我们希望它们的运行方式尽可能一致。列表管理员不需要使用典型Mailman站点中提供的众多选项,而他们需要的少数选项将通过Launchpad网络用户界面公开。
当时,Launchpad不是自由软件(这种情况在2009年发生了改变),因此我们必须以一种方式设计集成,即Mailman 2的GPLv2代码不会感染Launchpad。这导致了该集成设计中的一些非常棘手且效率低下的架构决策。由于Launchpad现在是根据AGPLv3许可的自由软件,因此这些 hack 现在不再需要,但是不得不这样做确实提供了一些非常宝贵的经验教训,说明了如何将没有网络用户界面的Mailman与外部系统集成。由此产生的愿景是一个核心引擎,它高效可靠地实现邮件列表操作,并且可以通过任何类型的网络前端管理,包括用Zope、Django或PHP编写的,或完全没有网络用户界面。
当时有许多技术可以实现这一点,实际上,Mailman与Launchpad的集成是基于XMLRPC的。但XMLRPC有一些问题,使其成为不太理想的协议。
Mailman 3已经采用表示状态转移 (REST) 模型来进行外部管理控制。REST基于HTTP,Mailman的默认对象表示是JSON。这些协议在各种编程语言和环境中无处不在且得到了很好的支持,使得将Mailman与第三方系统集成变得相当容易。REST非常适合Mailman 3,现在它的许多功能都通过REST API公开。
这是一个强大的范式,更多应用程序应该采用:提供一个实现其基本功能的良好核心引擎,并公开一个REST API来查询和控制它。REST API提供了另一种与Mailman集成的途径,其他途径包括使用命令行界面以及编写Python代码来访问内部API。这种架构非常灵活,可以在超越系统设计人员最初愿景的方式中使用和集成。
这种设计不仅允许在部署方面有更多选择,甚至允许系统的官方组件独立设计和实现。例如,Mailman 3的新官方网络用户界面在技术上是一个独立的项目,有自己的代码库,主要由经验丰富的网络设计师驱动。这些优秀的开发人员有权做出决策、创建设计并执行实现,而不会让核心引擎开发成为瓶颈。网络用户界面工作通过请求通过REST API公开的附加功能反馈到核心引擎实现中,但他们不必等待,因为他们可以在自己的终端模拟服务器端,并在核心引擎赶上来之前继续试验和开发网络用户界面。
我们计划将REST API用于更多的事情,包括允许对常见操作进行脚本编写,以及与IMAP或NNTP服务器集成,以便以替代方式访问档案。
GNU Mailman是最早采用国际化的Python程序之一。当然,由于Mailman通常不修改通过它发布的电子邮件内容,因此这些邮件可以是任何语言的,这取决于原始作者的选择。但是,当直接与Mailman交互时,无论是通过网络界面还是通过电子邮件命令,用户都希望使用他们自己的自然语言。
Mailman开创了Python世界中使用的许多国际化技术,但实际上它比大多数应用程序复杂得多。在典型的桌面环境中,自然语言是在用户登录时选择的,并且在整个桌面会话中保持不变。但是,Mailman是一个服务器应用程序,因此它必须能够处理数十种语言,与运行它的系统的语言无关。实际上,Mailman必须以某种方式确定要返回响应的语言上下文,并将文本翻译成该语言。有时,一个响应甚至可能涉及多种语言;例如,如果来自日本用户的弹回邮件要转发给说德语、意大利语和加泰罗尼亚语的列表管理员。
同样,Mailman开创了一些关键的Python技术来处理这种复杂的语言上下文。它利用一个库来管理一个语言堆栈,该堆栈可以随着上下文的改变而被推入和弹出,甚至可以在单个消息的处理过程中。它还实现了一个精心设计的方案,用于根据站点首选项、列表所有者首选项和语言选择来定制其响应模板。例如,如果列表所有者希望为她的一个列表定制响应模板,但只针对日本用户,她会将特定模板放置在文件系统的适当位置,这将覆盖更通用的默认设置。
虽然本文概述了Mailman 3的架构,并深入了解了该架构在15年的存在(通过三次重大重写)中是如何演变的,但Mailman中还有很多其他有趣的架构决策,我无法涵盖。这些包括配置子系统、测试基础设施、数据库层、正式接口的编程使用、存档、邮件列表样式、电子邮件命令和命令行界面,以及与发件邮件服务器的集成。如果您想了解更多详细信息,请与我们联系 mailman-developers 邮件列表。
以下是我们在重写开源生态系统中一个流行的、已建立的、稳定的组件时学到的一些教训。
unittests 或 doctests。进行 TDD 是获得信心的唯一方法,即您今天所做的更改不会在现有代码中引入回归。是的,TDD 有时可能需要更长的时间,但把它看作是对您未来代码质量的投资。从这个意义上说,没有良好的测试套件意味着您只是在浪费时间。记住这句话:未经测试的代码就是错误的代码。Subject: 标题中查找 Re: 前缀这样的操作也将是文本操作,而不是字节操作。Mailman 的原则是在尽可能早的阶段将所有传入数据从字节转换为 Unicode,在内部将文本作为 Unicode 处理,并且仅在传出时将其转换回字节。从一开始就明确区分您何时处理字节以及何时处理文本至关重要,因为在以后很难对这种基本模型转换进行改造。GNU Mailman 是一个充满活力的项目,拥有健康的使用者群,并提供了很多贡献机会。如果您想帮助我们,可以利用以下资源,希望您能这样做!
在本章节撰写期间,我们怀着沉痛的心情得知了菊地tokio(http://wiki.list.org/display/COM/TokioKikuchi)的逝世消息。他是一位日本教授,对Mailman做出了巨大贡献,尤其精通国际化和日本邮件用户代理的特性。他的离世将令我们深感惋惜。