Iron语言是一组非正式的语言实现,其名称中包含“Iron”,以纪念第一个Iron语言——IronPython。所有这些语言至少有一点共同之处——它们是面向公共语言运行时 (CLR) 的动态语言,CLR 通常称为 .NET Framework,并且它们构建在动态语言运行时 (DLR) 之上。(“CLR”是通用术语;.NET Framework 是微软的实现,还有开源的 Mono 实现。)DLR 是一组用于 CLR 的库,它们为 CLR 上的动态语言提供了更好的支持。IronPython 和 IronRuby 都用于几十个封闭和开源项目,并且都处于积极开发中;DLR 最初是一个开源项目,现在已包含在 .NET Framework 和 Mono 中。
从架构上讲,IronPython、IronRuby 和 DLR 既简单又复杂。从高级别来看,其设计类似于许多其他语言实现,包括解析器、编译器和代码生成器;但是,仔细观察,一些有趣的细节开始浮现:调用站点、绑定器、自适应编译和其他技术被用来使动态语言在为静态语言设计的平台上几乎与静态语言一样快。
Iron语言的历史始于 2003 年。Jim Hugunin 已经为 Java 虚拟机 (JVM) 编写了一个名为 Jython 的 Python 实现。当时,一些人(具体是谁,我不确定)认为当时新推出的 .NET Framework 公共语言运行时 (CLR) 不适合实现 Python 等动态语言。由于已经在 JVM 上实现了 Python,Jim 对微软如何让 .NET 比 Java 差得多感到好奇。在2006 年 9 月的一篇博文中,他写道
我想了解微软是如何搞砸的,以至于 CLR 成为比 JVM 更糟糕的动态语言平台。我的计划是用几个星期的时间构建一个 Python 在 CLR 上的原型实现,然后利用这项工作撰写一篇简短而精辟的文章,名为“为什么 CLR 是一个糟糕的动态语言平台”。随着我开发原型,我的计划迅速改变,因为我发现 Python 可以非常出色地运行在 CLR 上——在许多情况下,比基于 C 的实现明显更快。对于标准的pystone 基准测试,CLR 上的 IronPython 比基于 C 的实现快约 1.7 倍。
(名称中的“Iron”部分是当时 Jim 的公司 Want of a Nail Software 的名称的谐音。)
不久之后,Jim 被微软聘用,以使 .NET 成为一个更好的动态语言平台。Jim(以及其他一些人)通过将最初 IronPython 代码中与语言无关的部分分解出来,开发了 DLR。DLR 旨在为实现 .NET 的动态语言提供一个通用核心,并且是 .NET 4 的一项主要新功能。
在宣布 DLR 同时(2007 年 4 月),微软还宣布,除了基于 DLR 构建的新版 IronPython(IronPython 2.0)之外,他们还将在 DLR 之上开发 IronRuby 以展示 DLR 对多种语言的适应性。(2010 年 10 月,微软停止开发 IronPython 和 IronRuby,它们成为独立的开源项目。)使用 DLR 集成动态语言也将成为 C# 和 Visual Basic 的重要组成部分,并使用一个新关键字 (dynamic),允许这些语言轻松调用在 DLR 上实现的任何语言或任何其他动态数据源。CLR 已经是一个实现静态语言的良好平台,而 DLR 使动态语言成为一等公民。
微软之外的其他语言实现也使用 DLR,包括IronScheme 和IronJS。此外,微软的 PowerShell v3 将使用 DLR 而不是它自己的动态对象系统。
CLR 是针对静态类型语言设计的;类型知识深深地嵌入到运行时中,其关键假设之一是这些类型不会改变——变量永远不会改变其类型,或者类型在程序运行时永远不会添加或删除任何字段或成员。这对像 C# 或 Java 这样的语言来说很好,但是根据定义,动态语言不遵循这些规则。CLR 还为静态类型提供了一个公共对象系统,这意味着任何 .NET 语言都可以毫不费力地调用用任何其他 .NET 语言编写的对象。
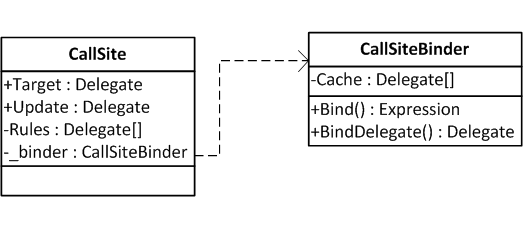
如果没有 DLR,每种动态语言都必须提供自己的对象模型;各种动态语言将无法调用另一种动态语言中的对象,并且 C# 将无法平等地对待 IronPython 和 IronRuby。因此,DLR 的核心是实现动态对象的标准方法,同时仍然允许通过使用绑定器为特定语言自定义对象的行为。它还包括一种称为调用站点缓存的机制,以确保动态操作尽可能快,以及一组用于构建表达式树的类,这些类允许代码作为数据存储并轻松操作。
CLR 还提供了一些对动态语言有用的其他功能,包括一个复杂的垃圾收集器;一个即时 (JIT) 编译器,它在运行时将公共中间语言 (IL) 字节码(.NET 编译器输出的内容)转换为机器代码;一个运行时自省系统,它允许动态语言调用用任何静态语言编写的对象;最后,动态方法(也称为轻量级代码生成),允许在运行时生成代码,然后以比静态方法调用略高的开销执行。(JVM 在 Java 7 中使用invokedynamic获得了类似的机制。)
DLR 设计的结果是,像 IronPython 和 IronRuby 这样的语言可以相互调用对象(以及任何其他 DLR 语言的对象),因为它们具有一个通用的动态对象模型。对这种对象模型的支持也已添加到 C# 4(使用dynamic关键字)和 Visual Basic 10(除了 VB 现有的“后期绑定”方法)中,以便它们也可以对对象执行动态调用。因此,DLR 使动态语言成为 .NET 上的一等公民。
有趣的是,DLR 完全实现为一组库,并且可以在 .NET 2.0 上构建和运行。实现它不需要更改 CLR。
每种语言实现都有两个基本阶段——解析(前端)和代码生成(后端)。在 DLR 中,每种语言都实现了自己的前端,其中包含语言解析器和语法树生成器;DLR 提供了一个通用的后端,它采用表达式树来生成供 CLR 使用的中间语言 (IL);CLR 将将 IL 传递给即时 (JIT) 编译器,后者生成在处理器上运行的机器代码。在运行时定义的代码(并使用eval运行)以类似的方式处理,只是所有操作都发生在eval调用站点而不是文件加载时。
实现语言前端的关键部分有几种不同的方法,虽然 IronPython 和 IronRuby 非常相似(毕竟它们是并行开发的),但它们在一些关键领域有所不同。IronPython 和 IronRuby 都具有相当标准的解析器设计——两者都使用标记器(也称为词法分析器)将文本拆分为标记,然后解析器将这些标记转换为表示程序的抽象语法树 (AST)。但是,这些语言的这些部分的实现完全不同。
IronPython 的标记器位于IronPython.Compiler.Tokenizer类中,解析器位于IronPython.Compiler.Parser类中。标记器是一个手写的状态机,它识别 Python 关键字、运算符和名称并生成相应的标记。每个标记还包含任何其他信息(例如常量或名称的值),以及在源代码中找到标记的位置,以帮助调试。然后,解析器获取此标记集并将其与 Python 语法进行比较,以查看它是否匹配合法的 Python 结构。
IronPython 的解析器是 LL(1)递归下降解析器。解析器将查看传入的标记,如果允许该标记,则调用一个函数,如果该标记不允许,则返回错误。递归下降解析器由一组互递归函数构建;这些函数最终实现一个状态机,每个新标记都会触发一个状态转换。与标记器一样,IronPython 的解析器也是手工编写的。
另一方面,IronRuby 有一个由 Gardens Point Parser Generator (GPPG) 生成的标记器和解析器。解析器在Parser.y文件(Languages/Ruby/Ruby/Compiler/Parser/Parser.y)中描述,这是一个yacc格式文件,它使用描述语法的规则在高级别描述 IronRuby 的语法。然后,GPPG 获取Parser.y并创建实际的解析器函数和表;结果是一个基于表的LALR(1) 解析器。生成的表是长整数数组,其中每个整数代表一个状态;根据当前状态和当前标记,表确定应转换到下一个状态。虽然 IronPython 的递归下降解析器非常易于阅读,但 IronRuby 的生成的解析器并非如此。转换表非常庞大(540 个不同的状态和超过 45,000 个转换),并且几乎不可能手动修改它。
最终,这是一个工程权衡——IronPython 的解析器足够简单,可以手动修改,但它也足够复杂,以至于模糊了语言的结构。另一方面,IronRuby 解析器使得在Parser.y文件中更容易理解语言的结构,但它现在依赖于一个使用自定义(尽管众所周知)领域特定语言的第三方工具,并且可能存在其自身的错误或怪癖。在这种情况下,IronPython 团队不想依赖于外部工具,而 IronRuby 团队则不介意。
然而,很明显的是,状态机在解析的每个阶段都非常重要。对于任何解析任务,无论多么简单,状态机始终是正确的答案。
无论是哪种语言,解析器的输出都是一个抽象语法树 (AST)。它以较高的层次描述了程序的结构,每个节点都直接映射到一个语言构造——语句或表达式。这些树可以在运行时进行操作,通常是在编译之前对程序进行优化。但是,语言的 AST 与语言绑定;DLR 需要操作不包含任何特定于语言的构造的树,只包含通用构造。
表达式树也是程序的一种表示形式,可以在运行时进行操作,但采用更低级、与语言无关的形式。在 .NET 中,节点类型位于 System.Linq.Expressions 命名空间中,所有节点类型都派生自抽象 Expression 类。(该命名空间是一个历史产物;表达式树最初是在 .NET 3.5 中添加的,用于实现 LINQ——语言集成查询——而 DLR 表达式树扩展了它。)然而,这些表达式树不仅仅涵盖表达式,因为还有用于 if 语句、try 块和循环的节点类型;在某些语言(例如 Ruby)中,这些是表达式而不是语句。
有一些节点可以涵盖编程语言可能需要的几乎所有功能。但是,它们往往是在相当低的级别上定义的——而不是拥有 ForExpression、WhileExpression 等,只有一个 LoopExpression,它与 GotoExpression 结合使用,可以描述任何类型的循环。为了在更高层次上描述一种语言,语言可以通过派生自 Expression 并覆盖 Reduce() 方法来定义自己的节点类型,该方法返回另一个表达式树。在 IronPython 中,解析树也是一个 DLR 表达式树,但它包含许多 DLR 通常无法理解的自定义节点(例如 ForStatement)。这些自定义节点可以简化为 DLR 可以理解的表达式树(例如 LoopExpression 和 GotoExpression 的组合)。一个自定义表达式节点可以简化为其他自定义表达式节点,因此简化过程递归进行,直到只剩下内在的 DLR 节点。IronPython 和 IronRuby 之间的一个关键区别在于,IronPython 的 AST 也是一个表达式树,而 IronRuby 的则不是。相反,IronRuby 的 AST 在进入下一阶段之前会转换为表达式树。是否将 AST 也作为表达式树实际上是否有用是有争议的,因此 IronRuby 没有以这种方式实现它。
每个节点类型都知道如何简化自身,并且通常只能以一种方式简化。对于来自树外部的转换——例如常量折叠等优化或 IronPython 对 Python 生成器的实现——使用 ExpressionVisitor 类的子类。ExpressionVisitor 具有一个 Visit() 方法,该方法调用 Expression 上的 Accept() 方法,并且 Expression 的子类覆盖 Accept() 以在 ExpressionVisitor 上调用特定的 Visit() 方法,例如 VisitBinary()。这是 Gamma 等人提出的访问者模式的教科书式实现——有一组固定的节点类型需要访问,并且可以对它们执行无限数量的操作。当表达式访问者访问一个节点时,它通常也会递归地访问其子节点,以及其子节点,依此类推,直到树的底部。但是,ExpressionVisitor 实际上无法修改它正在访问的表达式树,因为表达式树是不可变的。如果表达式访问者需要修改一个节点(例如删除子节点),它必须生成一个新的节点来替换旧节点,以及所有其父节点。
一旦创建、简化和访问了表达式树,最终需要执行它。虽然表达式树可以直接编译成 IL 代码,但 IronPython 和 IronRuby 会先将其传递给解释器,因为直接编译成 IL 对可能只执行几次的代码来说代价很高。
使用 JIT 编译器(如 .NET 所做的那样)的缺点之一是,它在启动时会造成时间损失,因为将 IL 字节码转换为处理器可以运行的机器码需要时间。与使用解释器相比,JIT 编译使代码在运行时速度更快,但初始成本可能过高,具体取决于正在执行的操作。例如,像 Web 应用程序这样的长期运行的服务器进程将受益于 JIT,因为启动时间大多无关紧要,但每个请求的时间至关重要,并且它倾向于重复运行相同的代码。另一方面,一个经常运行但只运行很短时间的程序,例如 Mercurial 命令行客户端,最好有一个较短的启动时间,因为它可能只运行每个代码块一次,并且 JIT 代码运行速度更快的事实并不能克服启动运行需要更长时间的事实。
.NET 不能直接执行 IL 代码;它始终会被 JIT 编译成机器代码,这需要时间。特别是,程序启动时间是 .NET Framework 的弱点之一,因为许多代码都需要 JIT 编译。虽然有一些方法可以避免静态 .NET 程序中的 JIT 损失(原生映像生成或NGEN),但它们不适用于动态程序。IronRuby 和 IronPython 不会始终直接编译到 IL,而是使用自己的解释器(位于 Microsoft.Scripting.Interpreter 中),该解释器不如 JIT 编译的代码快,但启动时间要短得多。解释器在不允许动态代码生成的场景中也很有用,例如在移动平台上;否则,DLR 语言将无法运行。
在执行之前,必须将整个表达式树包装在一个函数中,以便可以执行它。在 DLR 中,函数表示为 LambdaExpression 节点。虽然在大多数语言中,lambda 是一个匿名函数,但 DLR 没有名称的概念;所有函数都是匿名的。LambdaExpression 是独一无二的,因为它是唯一可以转换为委托的节点类型,.NET 使用其 Compile() 方法来调用第一类函数。委托类似于 C 函数指针——它只是一个可以调用的代码片段的句柄。
最初,表达式树被包装在一个 LightLambdaExpression 中,它也可以生成一个可以执行的委托,但它不是生成 IL 代码(然后调用 JIT),而是将表达式树编译成一个指令列表,然后在解释器的简单虚拟机上执行这些指令。解释器是一个简单的基于堆栈的解释器;指令从堆栈中弹出值,执行操作,然后将结果压回堆栈。每个指令都是一个派生自 Microsoft.Scripting.Interpreter.Instruction 的类的实例(例如 AddInstruction 或 BranchTrueInstruction),它具有描述它从堆栈中取出多少个项目、它将放入多少个项目以及一个 Run() 方法,该方法通过在堆栈上弹出和压入值并返回下一条指令的偏移量来执行指令。解释器获取指令列表并逐条执行它们,根据 Run() 方法的返回值向前或向后跳转。
一旦一段代码执行了特定次数,它将通过调用 LightLambdaExpression.Reduce() 转换为完整的 LambdaExpression,然后编译为 DynamicMethod 委托(在后台线程上进行一些并行处理),并且旧的委托调用站点将替换为更新、更快的委托。这大大降低了可能只调用几次的函数(例如程序的主函数)的执行成本,同时使常用函数尽可能快地运行。默认情况下,编译阈值设置为 32 次执行,但这可以通过命令行选项或主机程序更改,并且可以包括完全禁用编译或解释器。
无论通过解释器运行还是编译成 IL,语言的操作都不会由表达式树编译器硬编码。相反,编译器为每个可能为动态的操作(几乎所有操作)生成调用站点。这些调用站点使对象有机会实现动态行为,同时保持高性能。
在静态 .NET 语言中,所有关于应调用哪些代码的决策都是在编译时做出的。例如,考虑以下 C# 代码行
var z = x + y;
编译器知道 `x` 和 `y` 的类型以及是否可以将它们加在一起。编译器可以发出处理重载运算符、类型转换或任何其他可能使代码正常运行所需的代码,仅基于它知道的关于所涉及类型的静态信息。现在,考虑以下 Python 代码行
z = x + y
IronPython 编译器完全不知道在遇到它时这可能做什么,因为它不知道 x 和 y 的类型是什么,即使它知道,x 和 y 是否可以相加也可能在运行时发生变化。(原则上它可以,但 IronPython 和 IronRuby 都不进行类型推断。)而不是发出添加数字的 IL 代码,IronPython 发出一个将在运行时解析的调用站点。
调用站点是在运行时确定操作的占位符;它们作为 System.Runtime.CompilerServices.CallSite 类的实例实现。在像 Ruby 或 Python 这样的动态语言中,几乎每个操作都有一个动态组件;这些动态操作在表达式树中表示为 DynamicExpression 节点,表达式树编译器知道将其转换为调用站点。当创建调用站点时,它还不知道如何执行所需的操作;但是,它使用特定于所用语言的正确调用站点绑定器的实例创建,并且包含有关如何执行操作的所有必要信息。
每种语言将为每个操作都有不同的调用站点绑定器,并且绑定器通常知道许多不同的方法来执行操作,具体取决于传递给调用站点的参数。但是,生成这些规则代价很高(特别是将它们编译成用于执行的委托,这涉及调用 .NET JIT),因此调用站点具有一个多级调用站点缓存,用于存储已为以后使用创建的规则。
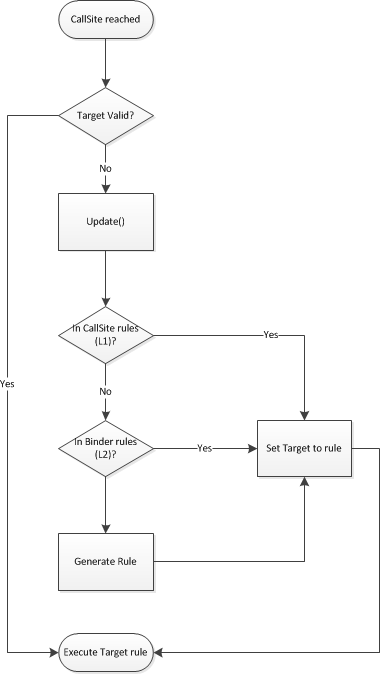
第一级,L0,是调用站点实例本身上的 CallSite.Target 属性。它存储此调用站点最近使用的规则;对于大量调用站点,这将是唯一需要的,因为它们只使用一组参数类型进行调用。调用站点还有一个缓存 L1,它存储另外 10 条规则。如果 Target 对此调用无效(例如,如果参数类型不同),则调用站点首先检查其规则缓存以查看它是否已在先前的调用中创建了正确的委托,并重用该规则而不是创建一个新的规则。
缓存中规则的存储由实际编译新规则所需的时间与检查现有规则所需的时间决定。粗略地说,.NET 对变量执行类型检查大约需要 10 ns(检查二元函数需要 20 ns 等),这是最常见的规则谓词类型。另一方面,编译一个简单的添加双精度数的方法大约需要 80 µs,或者长三个数量级。缓存的大小限制为防止浪费内存来存储在调用站点使用的每个规则;对于简单的加法,每个变体大约需要 1 KB 的内存。但是,分析表明,很少有调用站点超过 10 种变体。
最后,还有 L2 缓存,它存储在绑定器实例本身中。与调用站点关联的绑定器实例可能会存储一些额外的信息,使其特定于某个调用站点,但大量的调用站点在任何方面都不唯一,并且可以共享相同的绑定器实例。例如,在 Python 中,加法的基本规则在整个程序中都是相同的;它取决于+两侧的两种类型,仅此而已。程序中的所有加法运算都可以共享同一个绑定器,如果 L0 和 L1 缓存都未命中,则 L2 缓存包含从整个程序中收集的大量最近规则(128 个)。即使调用站点是第一次执行,它也很有可能在 L2 缓存中找到合适的规则。为了确保此功能最有效地工作,IronPython 和 IronRuby 都有一组规范的绑定器实例,用于加法等常见操作。
如果 L2 缓存未命中,则会要求绑定器为调用站点创建一个实现,同时考虑参数的类型(甚至可能包括值)。在上面的示例中,如果x和y是双精度数(或其他原生类型),则该实现只需将它们转换为双精度数并调用 IL add指令。绑定器还会生成一个测试,检查参数并确保它们对实现有效。实现和测试一起构成一个规则。在大多数情况下,实现和测试都以表达式树的形式创建和存储。(但是,调用站点基础结构不依赖于表达式树;它可以单独与委托一起使用。)
如果表达式树是用 C# 表示的,则代码将类似于
if(x is double && y is double) { // check for doubles
return (double)x + (double)y; // execute if doubles
}
return site.Update(site, x, y); // not doubles, so find/create another rule
// for these types
然后,绑定器从表达式树生成一个委托,这意味着规则被编译成 IL,然后编译成机器码。在添加两个数字的情况下,这很可能变成一个快速的类型检查,然后是一个添加数字的机器指令。即使涉及所有这些机制,最终结果也只比静态代码慢一点。IronPython 和 IronRuby 还包含一组用于基本类型加法等常见操作的预编译规则,这节省了时间,因为它们不必在运行时创建,但确实会占用磁盘上的额外空间。
除了语言基础设施之外,DLR 的另一个关键部分是语言(宿主语言)能够对在另一种语言(源语言)中定义的对象进行动态调用。为了使这成为可能,DLR 必须能够理解哪些操作对对象有效,无论它是用哪种语言编写的。Python 和 Ruby 具有非常相似的对象模型,但 JavaScript 具有根本不同的基于原型(而不是基于类)的类型系统。DLR 没有试图统一各种类型系统,而是将它们都视为基于 Smalltalk 风格的消息传递。
在消息传递的面向对象系统中,对象向其他对象发送消息(通常带有参数),并且对象可以返回另一个对象作为结果。因此,虽然每种语言都有自己关于对象是什么的想法,但通过将方法调用视为对象之间发送的消息,几乎所有对象都可以等价。当然,即使是静态 OO 语言在某种程度上也符合这种模型;使动态语言不同的原因是,在编译时不必知道要调用的方法,甚至该对象上根本不存在该方法(例如,Ruby 的method_missing),并且目标对象通常有机会拦截消息并在必要时以不同的方式处理它(例如,Python 的__getattr__)。
DLR 定义了以下消息
{Get|Set|Delete}Member:用于操作对象成员的操作{Get|Set|Delete}Index:用于索引对象(例如数组或字典)的操作Invoke、InvokeMember:调用对象或对象的成员CreateInstance:创建对象实例Convert:将对象从一种类型转换为另一种类型UnaryOperation、BinaryOperation:执行基于运算符的操作,例如取反(!)或加法(+)总而言之,这些操作应该足以实现几乎任何语言的对象模型。
由于 CLR 本身是静态类型的,因此动态语言对象仍然必须由静态类表示。通常的技术是使用一个静态类,例如PythonObject,并使实际的 Python 对象成为此类或其子类的实例。出于互操作性和性能方面的考虑,DLR 的机制要复杂得多。DLR 不处理特定于语言的对象,而是处理元对象,它们是System.Dynamic.DynamicMetaObject的子类,并具有处理所有上述消息的方法。每种语言都有自己的DynamicMetaObject子类,它们实现了该语言的对象模型,例如 IronPython 的MetaPythonObject。元类也有相应的具体类实现System.Dynamic.IDynamicMetaObjectProtocol接口,这是 DLR 如何识别动态对象的方式。
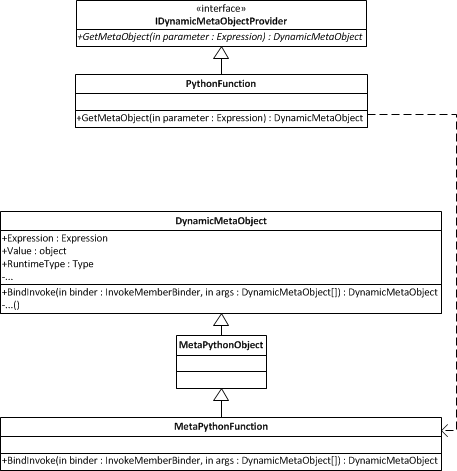
从实现IDynamicMetaObjectProtocol的类中,DLR 可以通过调用GetMetaObject()获取DynamicMetaObject。此DynamicMetaObject由语言提供,并根据该对象的要求实现绑定函数。每个DynamicMetaObject还具有底层对象的类型和值(如果可用)。最后,DynamicMetaObject存储一个表示迄今为止调用站点的表达式树以及该表达式上的任何限制,类似于调用站点绑定器。
当 DLR 正在编译对用户定义类上的方法的调用时,它首先创建一个调用站点(即CallSite类的实例)。调用站点启动如上所述的“动态调用站点”中所述的绑定过程,最终导致它调用OldInstance实例上的GetMetaObject(),该实例返回一个MetaOldInstance。(Python 有旧式类和新式类,但这在这里无关紧要。)接下来,调用绑定器(PythonGetMemberBinder.Bind()),该绑定器依次调用MetaOldInstance.BindGetMember();它返回一个新的DynamicMetaObject,描述如何在对象上查找方法名称。然后调用另一个绑定器PythonInvokeBinder.Bind(),它调用MetaOldInstance.BindInvoke(),用一个新的DynamicMetaObject包装第一个DynamicMetaObject,表示如何调用已查找的方法。这包括原始对象、查找方法名称的表达式树以及表示方法参数的DynamicMetaObject。
表达式中的最终DynamicMetaObject构建完成后,将使用其表达式树和限制来构建一个委托,然后将其返回到启动绑定的调用站点。从那里,代码可以存储在调用站点缓存中,使对象上的操作与其他动态调用一样快,并且几乎与静态调用一样快。
想要对动态语言执行动态操作的主机语言必须从DynamicMetaObjectBinder派生其绑定器。DynamicMetaObjectBinder将首先要求目标对象绑定操作(通过调用GetMetaObject()并经历上面描述的绑定过程),然后再回退到主机语言的绑定语义。因此,如果从 IronPython 程序访问 IronRuby 对象,则首先尝试使用 Ruby(目标语言)语义进行绑定;如果失败,DynamicMetaObjectBinder将回退到 Python(主机语言)语义。如果要绑定的对象不是动态的(即,它没有实现IDynamicMetaObjectProvider),例如来自 .NET 基类库的类,则使用主机语言的语义使用 .NET 反射来访问它。
语言在如何实现这一点方面确实具有一定的自由度;IronPython 的PythonInvokeBinder没有从InvokeBinder派生,因为它需要对 Python 对象执行一些特定于 Python 的额外处理。只要它只处理 Python 对象,就不会有任何问题;如果遇到实现了IDynamicMetaObjectProvider但不是 Python 对象的对象,它会转发到一个CompatibilityInvokeBinder类,该类确实继承自InvokeBinder并且可以正确处理外部对象。
如果回退无法绑定操作,它不会抛出异常;而是返回一个表示错误的DynamicMetaObject。然后,主机语言的绑定器将以适合主机语言的方式处理此错误;例如,从假设的 JavaScript 实现中访问 IronPython 对象上的缺失成员可能会返回undefined,而从 IronPython 对 JavaScript 对象执行相同的操作将引发AttributeError。
语言能够与动态对象一起工作的能力如果没有首先加载和执行用其他语言编写的代码的能力,那将毫无用处,为此,DLR 提供了一种用于托管其他语言的通用机制。
除了提供通用的语言实现细节之外,DLR 还提供了一个共享的托管接口。托管接口由主机语言(通常是像 C# 这样的静态语言)用于执行用另一种语言(如 Python 或 Ruby)编写的代码。这是一种常见的技术,允许最终用户扩展应用程序,而 DLR 通过使使用任何具有 DLR 实现的脚本语言变得微不足道,从而更进一步。托管接口有四个关键部分:运行时、引擎、源和作用域。
ScriptRuntime通常在应用程序中的所有动态语言之间共享。运行时处理呈现给已加载语言的所有当前程序集引用,提供用于快速执行文件的方法,并提供用于创建新引擎的方法。对于简单的脚本任务,运行时是唯一需要使用的接口,但 DLR 还提供了一些类,可以更详细地控制脚本的运行方式。
通常,每种脚本语言只使用一个ScriptEngine。DLR 的元对象协议意味着程序可以加载来自多种语言的脚本,并且每种语言创建的对象都可以无缝地互操作。引擎包装特定于语言的LanguageContext(例如PythonContext或RubyContext),用于执行来自文件或字符串的代码以及对来自不支持 DLR 的语言(例如 .NET 4 之前的 C#)的动态对象执行操作。引擎是线程安全的,可以并行执行多个脚本,只要每个线程都有自己的作用域即可。它还提供用于创建脚本源的方法,这允许更细粒度地控制脚本执行。
ScriptSource保存要执行的代码块;它将SourceUnit对象(保存实际代码)绑定到创建该源的ScriptEngine。此类允许代码被编译(这会生成可以缓存的CompiledCode对象)或直接执行。如果要重复执行一段代码,最好先编译,然后执行编译后的代码;对于仅执行一次的脚本,最好直接执行。
最后,无论代码如何执行,都必须提供ScriptScope供代码在其中执行。作用域用于保存所有脚本变量,如果需要,可以预先加载主机中的变量。这允许主机在脚本开始运行时向脚本提供自定义对象——例如,图像编辑器可以提供一种方法来访问脚本正在处理的图像的像素。脚本执行完成后,可以从作用域中读取它创建的任何变量。作用域的其他主要用途是提供隔离,以便可以同时加载和执行多个脚本而不会相互干扰。
需要注意的是,所有这些类都是由 DLR 提供的,而不是语言本身;只有引擎使用的LanguageContext来自语言实现。语言上下文提供了主机所需的所有功能——加载代码、创建作用域、编译、执行以及对动态对象的运算——而 DLR 托管类则提供了一个更易用的接口来访问这些功能。因此,相同的托管代码可以用于托管任何基于 DLR 的语言。
对于用 C 编写的动态语言实现(例如最初的 Python 和 Ruby),必须编写特殊的包装代码来访问非动态语言编写的代码,并且必须为每种支持的脚本语言重复此操作。虽然像 SWIG 这样的软件可以使这项工作更容易,但为程序添加 Python 或 Ruby 脚本接口并公开其对象模型以供外部脚本操作仍然不是一件容易的事。但是,对于 .NET 程序,添加脚本就像设置运行时、将程序的程序集加载到运行时以及使用ScriptScope.SetVariable()使程序的对象可供脚本使用一样简单。向 .NET 应用程序添加脚本支持只需几分钟即可完成,这是 DLR 的一个巨大优势。
由于 DLR 从一个独立的库演变成 CLR 的一部分,因此有些部分位于 CLR 中(调用站点、表达式树、绑定器、代码生成和动态元对象),而有些部分是 IronLanguages 开源项目的一部分(托管、解释器以及此处未讨论的其他一些部分)。位于 CLR 中的部分也包含在 IronLanguages 项目的Microsoft.Scripting.Core中。DLR 部分被分成两个程序集,Microsoft.Scripting和Microsoft.Dynamic——前者包含托管 API,后者包含 COM 互操作、解释器和一些其他动态语言共有的代码。
语言本身也分为两部分:IronPython.dll和IronRuby.dll实现了语言本身(解析器、绑定器等),而IronPython.Modules.dll和IronRuby.Libraries.dll则实现了经典 Python 和 Ruby 实现中用 C 实现的标准库部分。
DLR 是一个基于静态运行时构建的、面向动态语言的语言中立平台的一个很好的例子。它用来实现高性能动态代码的技术难以正确实现,因此 DLR 采用了这些技术并使之可用于每个动态语言实现。
IronPython 和 IronRuby 是如何在 DLR 之上构建语言的很好的例子。它们的实现非常相似,因为它们是由紧密合作的团队同时开发的,但它们在实现上仍然存在显着差异。拥有多个共同开发的不同语言(IronPython、IronRuby、一个原型 JavaScript 以及神秘的 VBx——一个完全动态版本的 VB),以及 C# 和 VB 的动态特性,确保了 DLR 设计在开发过程中得到了充分的测试。
IronPython、IronRuby 和 DLR 的实际开发与当时微软内部的大多数项目处理方式非常不同——它是一个非常敏捷的迭代开发模型,从第一天起就持续集成。这使得他们在需要时能够非常快速地进行更改,这很好,因为 DLR 在开发早期就与 C# 的动态特性绑定在一起。虽然 DLR 测试非常快,只需要十几秒钟,但语言测试运行时间过长(即使并行执行,IronPython 测试套件也需要大约 45 分钟);改进这一点可以提高迭代速度。最终,这些迭代收敛到当前的 DLR 设计,该设计在某些方面看起来过于复杂,但在整体上却非常完美地结合在一起。
将 DLR 与 C# 绑定至关重要,因为它确保了 DLR 有一个位置和一个“目的”,但是一旦 C# 的动态特性完成,政治气候就发生了变化(与经济衰退同时发生),Iron 语言失去了公司内部的支持。例如,托管 API 从未进入 .NET Framework(而且它们极不可能进入);这意味着同样基于 DLR 的 PowerShell 3 使用的托管 API 集与 IronPython 和 IronRuby 完全不同,尽管它们的所有对象仍然可以像上面描述的那样交互。(一些 DLR 团队成员后来参与了代号为“Roslyn”的 C# 编译器即服务库的开发,它与 IronPython 和 IronRuby 托管 API 惊人地相似。)但是,由于开源许可的奇妙之处,它们将继续生存,甚至繁荣发展。