Git 使得许多协作者可以使用点对点仓库网络来维护数字工作内容(通常但不仅限于代码)。它支持分布式工作流程,允许工作内容最终收敛或暂时分叉。
本章将展示 Git 的幕后工作方式,以及它与其他版本控制系统 (VCS) 的区别。
为了更好地理解 Git 的设计理念,了解 Git 项目在 Linux 内核社区中的起源很有帮助。
与当时大多数商业软件项目相比,Linux 内核非常特殊,因为它拥有大量的提交者,以及贡献者参与度和对现有代码库的了解程度存在很大的差异。内核多年来一直通过 tar 包和补丁进行维护,核心开发社区一直在努力寻找一种能够满足他们大部分需求的 VCS。
Git 诞生于 2005 年,是为了满足这些需求并解决当时的痛点。当时,Linux 内核代码库由不同的核心开发者使用两个 VCS(BitKeeper 和 CVS)进行管理。与当时流行的开源 VCS 相比,BitKeeper 提供了不同的 VCS 历史血统视图。
在 BitKeeper 制造商 BitMover 宣布将撤销部分 Linux 内核核心开发者的许可证后的几天内,Linus Torvalds 匆忙开始了 Git 的开发工作,最终成为了 Git。他首先编写了一组脚本,帮助他管理电子邮件补丁,以便一次应用一个补丁。这组初始脚本的目的是能够快速中止合并,以便维护者可以在补丁流的中间修改代码库以手动合并,然后继续合并后续补丁。
从一开始,Torvalds 就对 Git 只有一个哲学目标——成为反 CVS——以及三个可用性设计目标
这些设计目标在一定程度上已经实现并保持,我将尝试通过剖析 Git 如何使用有向无环图 (DAG) 来存储内容、使用引用指针来指向头、对象模型表示以及远程协议;以及最后 Git 如何跟踪树的合并来证明这一点。
尽管 BitKeeper 影响了 Git 的最初设计,但它在根本上以不同的方式实现,并允许更多分布式和仅本地工作流程,而这些工作流程在 BitKeeper 中是不可能的。 Monotone 是一款 2003 年开始的开源分布式 VCS,它很可能是 Git 早期开发过程中的另一个灵感来源。
分布式版本控制系统提供了极大的工作流程灵活性,通常以牺牲简单性为代价。分布式模型的具体优势包括
在 Git 项目启动的同一时期,另外三个开源分布式 VCS 项目也启动了。(其中一个,Mercurial,在《开源应用程序架构》第一卷中有所讨论。)所有这些 dVCS 工具都提供了略微不同的方式来实现高度灵活的工作流程,而之前的集中式 VCS 无法直接处理这些工作流程。注意:Subversion 拥有一个名为 SVK 的扩展,由不同的开发者维护,以支持服务器到服务器的同步。
如今,流行且积极维护的开源 dVCS 项目包括 Bazaar、Darcs、Fossil、Git、Mercurial 和 Veracity。
现在是退一步看看 Git 的替代 VCS 解决方案的好时机。了解它们之间的差异将使我们能够探索开发 Git 时面临的架构选择。
版本控制系统通常有三个核心功能需求,即
注意:上面的第三个要求不是所有 VCS 的功能要求。
在 VCS 世界中,最常见的存储内容的设计选择是基于增量的变更集,或者使用有向无环图 (DAG) 内容表示。
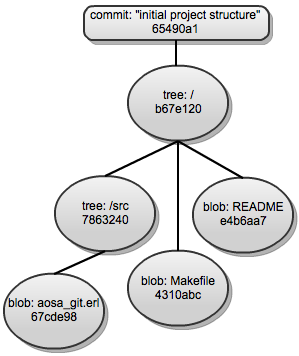
基于增量的变更集封装了两个版本扁平化内容之间的差异,以及一些元数据。将内容表示为有向无环图涉及到对象形成一个层次结构,该层次结构反映了内容的系统树作为提交的快照(尽可能重用树中未更改的对象)。Git 使用不同类型的对象将内容存储为有向无环图。本章后面的“对象数据库”部分将描述可以形成 Git 仓库中 DAG 的不同类型的对象。
Git 再次使用 DAG,这次是用来存储它的历史记录。每个提交都包含有关其祖先的元数据;Git 中的提交可以有一个或多个(理论上无限多个)父提交。例如,Git 仓库中的第一个提交将没有父提交,而三次合并的结果将有三个父提交。
Git 与 Subversion 及其线性历史记录祖先之间的另一个主要区别是它能够直接支持分支,这将记录大多数合并历史记录情况。
Git 使用有向无环图来存储内容,从而实现完全的分支功能。文件的历史记录一直链接到其目录结构(通过表示目录的节点)到根目录,然后链接到提交节点。这个提交节点又可以有一个或多个父节点。这为 Git 提供了两个属性,使我们能够以比从 RCS 派生的 VCS 家族更明确的方式推理历史记录和内容,即
VCS 解决方案以三种方式之一处理将工作副本分发给项目中的协作者
为了演示每种主要设计选择的优势和局限性,我们将考虑一个 Subversion 仓库和一个 Git 仓库(在服务器上),它们具有等效的内容(即 Git 仓库中默认分支的 HEAD 与 Subversion 仓库中主干上的最新修订版具有相同的内容)。一位名为 Alex 的开发者拥有 Subversion 仓库的本地签出和 Git 仓库的本地克隆。
假设 Alex 在 Subversion 仓库的本地签出中对一个 1 MB 的文件进行更改,然后提交更改。在本地,文件的签出反映了最新的更改,并且本地元数据已更新。在 Alex 对集中式 Subversion 仓库进行提交时,会生成文件之前快照和新更改之间的差异,并且此差异存储在仓库中。
将此与 Git 的工作方式进行对比。当 Alex 对 Git 本地克隆中的等效文件进行相同的修改时,更改将首先在本地记录,然后 Alex 可以将本地挂起的提交“推送”到公共仓库,以便与项目中的其他协作者共享工作。内容更改在每个存在提交的 Git 仓库中以相同的方式存储。在本地提交(最简单的情况)时,本地 Git 仓库将创建一个新对象,该对象表示更改文件的文件(其所有内容都在其中)。对于更改文件上方的每个目录(以及仓库根目录),将创建一个具有新标识符的新树对象。从新创建的根树对象开始创建 DAG,指向 blob(在文件内容在本次提交中未更改的情况下重用现有的 blob 引用),并在之前树层次结构中替换该文件的先前 blob 对象,引用新创建的 blob。(blob 表示存储在仓库中的文件。)
此时,提交仍然是 Alex 本地设备上当前 Git 克隆的本地提交。当 Alex 将提交“推送”到公开可访问的 Git 仓库时,此提交将被发送到该仓库。在公共仓库验证提交是否可以应用于分支后,公共仓库将存储与最初在本地 Git 仓库中创建的相同的对象。
Git 场景中有更多的活动部分,无论是在幕后还是对用户而言,都需要他们明确表达将更改与远程仓库共享的意图,而不是将更改作为本地提交进行跟踪。然而,这两个层次的额外复杂性都为团队提供了更大的工作流程和发布能力灵活性,如上面“Git 的起源”部分所述。
在 Subversion 场景中,协作者不需要记住在准备让其他人查看所做更改时将更改推送到公共远程仓库。当向集中式 Subversion 仓库发送对较大型文件的少量修改时,存储的增量比为每个版本存储完整的文件内容更有效。但是,正如我们稍后将看到的,Git 在某些情况下利用了这种解决方法。
如今,Git 生态系统包括许多在多个操作系统(包括 Windows,它最初几乎不支持)上的命令行和 UI 工具。大多数这些工具主要构建在 Git 核心工具包之上。
由于 Linus 最初编写 Git 的方式,以及它在 Linux 社区中的起源,它是在非常符合 Unix 命令行工具设计理念的情况下编写的。
Git 工具包分为两部分:管道和瓷器。管道由低级命令组成,这些命令使基本内容跟踪和有向无环图 (DAG) 的操作成为可能。瓷器是 git 命令的一个较小的子集,大多数 Git 最终用户可能需要使用这些命令来维护仓库并在仓库之间进行通信以进行协作。
虽然工具包设计提供了足够的命令来为许多脚本编写者提供对功能的细粒度访问,但应用程序开发人员抱怨缺乏可链接的 Git 库。由于 Git 二进制文件调用 die(),它不是可重入的,GUI、Web 接口或运行时间更长的服务必须分叉/执行对 Git 二进制文件的调用,这可能很慢。
正在努力改善应用程序开发人员的情况;有关更多信息,请参见“当前和未来工作”部分。
让我们动手实践,深入了解在本地使用 Git,即使只是为了理解一些基本概念。
首先,在我们的本地文件系统(使用类 Unix 操作系统)上创建一个新的初始化 Git 仓库,我们可以执行以下操作:
$ mkdir testgit $ cd testgit $ git init
现在,我们拥有一个空的但已初始化的 Git 仓库,位于我们的 testgit 目录中。我们可以进行分支、提交、标签操作,甚至与其他本地和远程 Git 仓库进行通信。只需使用少量 git 命令,甚至可以与其他类型的 VCS 仓库进行通信。
git init 命令在 testgit 内创建一个 .git 子目录。让我们看一下它的内部。
tree .git/
.git/
|-- HEAD
|-- config
|-- description
|-- hooks
| |-- applypatch-msg.sample
| |-- commit-msg.sample
| |-- post-commit.sample
| |-- post-receive.sample
| |-- post-update.sample
| |-- pre-applypatch.sample
| |-- pre-commit.sample
| |-- pre-rebase.sample
| |-- prepare-commit-msg.sample
| |-- update.sample
|-- info
| |-- exclude
|-- objects
| |-- info
| |-- pack
|-- refs
|-- heads
|-- tags
上面的 .git 目录默认情况下是根工作目录 testgit 的子目录。它包含几种不同类型的文件和目录。
.git/config、.git/description 和 .git/info/exclude 文件主要用于配置本地仓库。.git/hooks 目录包含在仓库生命周期事件中可执行的脚本。.git/index 文件(在我们上面的树形列表中尚未出现)将为我们的工作目录提供一个暂存区。.git/objects 目录是默认的 Git 对象数据库,它包含所有内容或指向本地内容的指针。所有对象一旦创建就不可变。.git/refs 目录是存储本地和远程分支、标签和头的引用指针的默认位置。引用是指向对象的指针,通常是 tag 或 commit 类型。引用在对象数据库之外进行管理,以便引用可以在仓库演进时更改其指向的位置。引用的特殊情况可能指向其他引用,例如 HEAD。.git 目录是实际的仓库。包含工作文件集的目录是工作目录,它通常是 .git 目录(或仓库)的父目录。如果要创建一个没有工作目录的 Git 远程仓库,可以使用 git init --bare 命令进行初始化。这将在根目录下只创建简化的仓库文件,而不是在工作树下创建仓库作为子目录。
另一个非常重要的文件是Git 索引:.git/index。它提供本地工作目录和本地仓库之间的暂存区。索引用于暂存单个文件(或多个文件)中的特定更改,以便将它们一起提交。即使您对各种类型的功能进行更改,也可以将这些更改一起进行提交,以便在提交消息中更合理地描述它们。要选择性地暂存文件或文件集中的特定更改,可以使用 git add -p。
Git 索引默认情况下存储在仓库目录中的单个文件中。这三个区域的路径可以使用环境变量进行自定义。
了解这三个区域(仓库、索引和工作区域)在执行一些核心 Git 命令期间的交互非常有用。
git checkout [分支]
这将把本地仓库的 HEAD 引用移动到分支引用路径(例如 refs/heads/master),用此头数据填充索引,并将工作目录刷新为表示该头处的树。
git add [文件]
这将交叉引用指定的文件的校验和与 Git 索引中的相应条目,以查看是否需要使用工作目录的版本更新暂存文件的索引。Git 目录(或仓库)中没有任何变化。
让我们通过检查 .git 目录(或仓库)下文件的內容,更具体地了解这意味着什么。
$ GIT_DIR=$PWD/.git $ cat $GIT_DIR/HEAD ref: refs/heads/master $ MY_CURRENT_BRANCH=$(cat .git/HEAD | sed 's/ref: //g') $ cat $GIT_DIR/$MY_CURRENT_BRANCH cat: .git/refs/heads/master: No such file or directory
我们得到一个错误,因为在向 Git 仓库进行任何提交之前,除了 Git 中的默认分支 master 外,不存在其他分支,无论它是否已经存在。
现在,如果我们进行新的提交,则默认情况下会为该提交创建 master 分支。让我们执行此操作(在同一个 shell 中继续,保留历史记录和上下文)。
$ git commit -m "Initial empty commit" --allow-empty $ git branch * master $ cat $GIT_DIR/$MY_CURRENT_BRANCH 3bce5b130b17b7ce2f98d17b2998e32b1bc29d68 $ git cat-file -p $(cat $GIT_DIR/$MY_CURRENT_BRANCH)
我们开始看到的是 Git 对象数据库中的内容表示。

Git 有四个基本原始对象,本地仓库中的所有类型的内容都是围绕它们构建的。每种对象类型具有以下属性:类型、大小和内容。原始对象类型是
所有对象原语都由 SHA 引用,SHA 是一个 40 位的对象标识符,具有以下属性
SHA 的前两个属性,与对象的标识有关,在启用 Git 的分布式模型(Git 的第二个目标)方面最为有用。后一个属性实现了针对损坏的某些保障措施(Git 的第三个目标)。
尽管使用基于 DAG 的存储用于内容存储和合并历史记录带来了理想的结果,但对于许多仓库来说,增量存储比使用松散的 DAG 对象更节省空间。
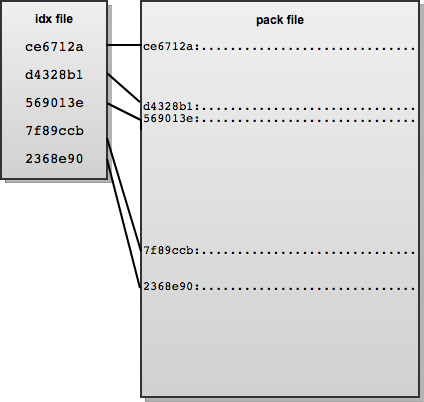
Git 通过以压缩格式打包对象来解决存储空间问题,使用索引文件指向偏移量来定位相应打包文件中特定对象的位置。
我们可以使用 git count-objects 统计本地 Git 仓库中的松散(或未打包)对象的數量。现在,我们可以让 Git 打包对象数据库中的松散对象,删除已打包的松散对象,并根据需要使用 Git 管道命令查找冗余的包文件。
Git 中的包文件格式已经发展,最初的格式在索引文件中存储了包文件和索引文件的 CRC 校验和。但是,这意味着压缩数据中可能存在无法检测的损坏,因为重新打包阶段不涉及任何进一步的检查。包文件格式的版本 2 通过在包索引文件中包含每个压缩对象的 CRC 校验和来解决这个问题。版本 2 还允许包文件大于 4 GB,而最初的格式不支持。为了快速检测包文件损坏,包文件末尾包含该文件中所有 SHA 的有序列表的 20 字节 SHA1 校验和。较新包文件格式的重点在于帮助实现 Git 的第二个可用性设计目标,即防止数据损坏。
对于远程通信,Git 会计算需要通过网络发送以同步仓库(或只是分支)的提交和内容,并动态生成包文件格式以使用客户端的所需协议发送回。
如前所述,Git 在合并历史记录方法方面与 RCS 系列的 VCS 有根本的不同。例如,Subversion 以线性方式表示文件或树的历史记录;具有较高修订号的任何内容将取代之前的任何内容。直接不支持分支,只能通过仓库内的未强制执行的目录结构进行。
让我们首先使用一个示例来展示在维护工作的多個分支时,这可能带来的问题。然后,我们将查看一个场景来展示它的局限性。
在 Subversion 中的典型根目录 branches/branch-name 中处理“分支”时,我们正在处理与 trunk 相邻的目录子树(通常,实时或master 等效代码位于其中)。假设此分支用于表示 trunk 树的并行开发。
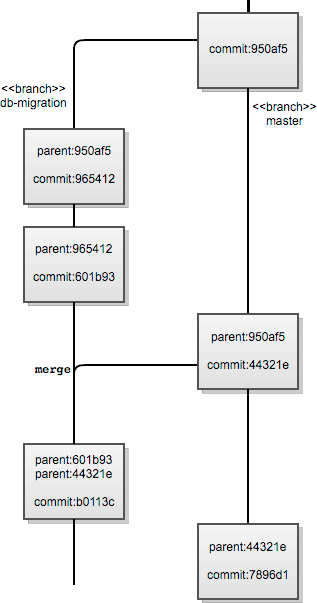
例如,我们可能正在重写代码库以使用不同的数据库。在我们重写过程中的某一部分,我们希望合并来自另一个分支子树(而不是主干)的上游更改。我们合并这些更改(必要时手动),然后继续进行重写。当天晚些时候,我们完成数据库供应商迁移代码更改,并将更改合并到 trunk 中。线性历史 VCS(如 Subversion)处理此问题的方式存在的问题是,无法知道来自其他分支的更改集现在是否包含在主干中。
基于 DAG 的合并历史记录 VCS(如 Git)可以很好地处理这种情况。假设另一个分支不包含未合并到我们的数据库供应商迁移分支(在我们的 Git 仓库中称为 db-migration)中的提交,我们可以从提交对象父关系中确定,db-migration 分支上的提交包含另一个上游分支的尖端(或 HEAD)。请注意,提交对象可以具有零个或多个(仅受合并者能力限制)父对象。因此,db-migration 分支上的合并提交知道它通过父对象的 SHA 哈希值合并了当前分支的当前 HEAD 和另一个上游分支的 HEAD。master(Git 中的 trunk 等效项)中的合并提交也是如此。
使用基于 DAG 的(和基于线性的)合并历史记录很难明确回答的一个问题是,哪些提交包含在每个分支中。例如,在上述场景中,我们假设我们将两个分支的所有更改都合并到了每个分支中。情况可能并非如此。
对于更简单的情况,Git 能够从其他分支中挑选提交到当前分支,假设提交可以干净地应用于该分支。
如前所述,我们今天所知的 Git 核心基于 Unix 世界的工具包设计理念,这对于脚本编写非常方便,但对于嵌入到更长时间运行的应用程序或服务中或与其链接不太有用。虽然现在许多流行的集成开发环境中都提供 Git 支持,但添加此支持并维护它比集成提供易于链接和共享库以供多个平台使用的 VCS 的支持更具挑战性。
为了解决这个问题,Shawn Pearce(来自 Google 开放源代码计划办公室)带头努力创建一个可链接的 Git 库,该库具有更宽松的许可证,不会限制库的使用。这被称为 libgit2。它直到去年一位名叫 Vincent Marti 的学生将其选为他的 Google 暑期代码项目才获得广泛的关注。从那时起,Vincent 和 Github 工程师一直在为 libgit2 项目做出贡献,并为许多其他流行语言创建了绑定,例如 Ruby、Python、PHP、.NET 语言、Lua 和 Objective-C。
Shawn Pearce 还启动了一个名为 JGit 的 BSD 许可的纯 Java 库,该库支持对 Git 仓库的许多常见操作。它现在由 Eclipse 基金会维护,用于 Eclipse IDE Git 集成。
除了 Git 核心项目之外,其他有趣的实验性开源努力包括使用替代数据存储作为 Git 对象数据库的后端的许多实现,例如
所有这些开源项目都独立于 Git 核心项目进行维护。
正如你所见,现在有很多方法可以使用 Git 格式。Git 的面貌不再仅仅是 Git 核心项目工具包的命令行界面;而是存储库格式和协议,可以在存储库之间共享。
截至撰写本文时,根据开发人员的说法,大多数这些项目尚未发布稳定版本,因此该领域的工作仍需进行,但 Git 的未来一片光明。
在软件开发中,每个设计决策最终都是权衡取舍。作为 Git 版本控制的重度用户,以及围绕 Git 对象数据库模型开发软件的人,我对 Git 的现状充满了热爱。因此,这些经验教训更多地反映了对 Git 的一些常见抱怨,这些抱怨源于 Git 核心开发人员的设计决策和关注重点。
开发人员和评估 Git 的管理人员最常见的抱怨之一是缺乏与其他 VCS 工具相当的 IDE 集成。Git 的工具包设计使得将 Git 与 IDE 和相关工具集成比其他现代 VCS 工具更具挑战性。
在 Git 历史的早期,一些命令是作为 shell 脚本实现的。这些 shell 脚本命令的实现使得 Git 难以移植,特别是移植到 Windows。我相信 Git 核心开发人员对此并不担心,但由于 Git 开发初期普遍存在的可移植性问题,它对 Git 在大型组织中的采用产生了负面影响。如今,一个名为 Git for Windows 的项目由志愿者发起,旨在确保及时将 Git 的新版本移植到 Windows。
围绕工具包设计和大量管道命令设计 Git 的一个间接结果是,新用户很容易迷路;从对所有可用子命令感到困惑,到无法理解错误消息,因为底层管道任务失败,新用户有很多地方容易出错。这对一些开发团队采用 Git 来说造成了困难。
即使有这些关于 Git 的抱怨,我对 Git 核心项目未来的开发以及由此衍生出来的所有相关开源项目充满期待。