Glasgow Haskell 编译器 (GHC) 起源于 1990 年代初由英国政府资助的一个学术研究项目,该项目的目标是:
GHC 现已诞生 20 多年,自问世以来一直处于持续活跃的开发之中。如今,GHC 发行版被数十万人下载,Haskell 库的在线资源库拥有超过 3000 个包,GHC 被用于许多本科课程教授 Haskell,并且越来越多的商业案例依赖 Haskell。
在 GHC 的生命周期中,它通常只有两到三名活跃开发者,尽管对 GHC 贡献过代码的人数已达数百人。虽然我们 GHC 主要开发人员的最终目标是进行研究而不是编写代码,但我们认为开发 GHC 是一个必不可少的先决条件:研究成果被反馈到 GHC 中,以便 GHC 可以作为进一步研究的基础,这些研究建立在这些先前的想法之上。此外,重要的是 GHC 必须是一款工业级产品,因为这会使使用它产生的研究结果更具信服力。因此,虽然 GHC 充满了前沿的研究理念,但我们投入了大量精力来确保它能够可靠地用于生产环境。这两个看似矛盾的目标之间往往存在一些矛盾,但总的来说,我们找到了一个既能满足研究需求又能满足生产使用需求的路径。
在本章中,我们想概述一下 GHC 的架构,并重点介绍一些在 GHC 中取得成功的关键理念(以及一些没有成功的理念)。希望在接下来的几页中,你能对我们如何成功地在一个 20 多年来一直保持活跃的大型软件项目中保持代码库不会因为自身重量而崩溃,并且在大多数人认为开发团队规模很小的情况下实现这一点有所了解。
Haskell 是一种函数式编程语言,由名为“Haskell 报告”的文档定义,其最新修订版为 Haskell 2010 [Mar10]。Haskell 由 1990 年几位对函数式语言感兴趣的学术研究界成员创建,旨在解决缺乏一种可以作为他们研究中心点的通用语言的问题。
Haskell 在众多编程语言中脱颖而出的两大特点是:
Haskell 也是强类型的,同时支持类型推断,这意味着类型注解很少需要。
有兴趣了解 Haskell 完整历史的人应该阅读 [HHPW07]。
在最高级别,GHC 可以分为三个不同的部分:
Int 类型之类的低级功能。其他库则是更高级的、独立于编译器的库,例如 Data.Map 库。事实上,这三个部分完全对应于 GHC 源代码树中的三个子目录:分别是 compiler、libraries 和 rts。
在这里,我们不会花太多时间讨论引导库,因为它们在架构方面基本没有意义。所有关键的设计决策都体现在编译器和运行时系统中,因此我们将把本章的其余部分专门讨论这两个组件。
我们上次衡量 GHC 中代码行数是在 1992 年(“Glasgow Haskell 编译器:技术概述”,JFIT 技术会议摘要,1992 年),因此看看自那时以来情况发生了怎样的变化很有趣。图 5.1 显示了 GHC 中代码行数的细分,按主要组件划分,比较了当前计数与 1992 年的计数。
| 模块 | 行数(1992) | 行数(2011) | 增长 |
|---|---|---|---|
| 编译器 | |||
| 主程序 | 997 | 11,150 | 11.2 |
| 解析器 | 1,055 | 4,098 | 3.9 |
| 重命名器 | 2,828 | 4,630 | 1.6 |
| 类型检查 | 3,352 | 24,097 | 7.2 |
| 去糖化 | 1,381 | 7,091 | 5.1 |
| 核心转换 | 1,631 | 9,480 | 5.8 |
| STG 转换 | 814 | 840 | 1 |
| 数据并行 Haskell | — | 3,718 | — |
| 代码生成 | 2913 | 11,003 | 3.8 |
| 原生代码生成 | — | 14,138 | — |
| LLVM 代码生成 | — | 2,266 | — |
| GHCi | — | 7,474 | — |
| Haskell 抽象语法 | 2,546 | 3,700 | 1.5 |
| 核心语言 | 1,075 | 4,798 | 4.5 |
| STG 语言 | 517 | 693 | 1.3 |
| C--(以前称为抽象 C) | 1,416 | 7,591 | 5.4 |
| 标识符表示 | 1,831 | 3,120 | 1.7 |
| 类型表示 | 1,628 | 3,808 | 2.3 |
| Prelude 定义 | 3,111 | 2,692 | 0.9 |
| 实用程序 | 1,989 | 7,878 | 3.96 |
| 分析 | 191 | 367 | 1.92 |
| 编译器总计 | 28,275 | 139,955 | 4.9 |
运行时系统 | |||
| 所有 C 和 C-- 代码 | 43,865 | 48,450 | 1.10 |
这些数字中有一些值得注意的地方:
Main 组件中添加了许多代码;这部分是因为以前有一个 3,000 行的 Perl 脚本,称为“驱动程序”,它被重写为 Haskell,并被移入 GHC 本身,同时也因为添加了对编译多个模块的支持。我们可以将编译器分为三个部分:
Hsc),它负责编译单个 Haskell 源文件。正如你所料,大部分工作都发生在这里。Hsc 的输出取决于选择了哪个后端:汇编、LLVM 代码或字节码。Hsc 组成在一起,以将 Haskell 源文件编译为目标代码。例如,Haskell 源文件可能需要在传递给 Hsc 之前使用 C 预处理器进行预处理,并且 Hsc 的输出通常是一个汇编文件,该文件必须传递给汇编器以创建目标文件。编译器不仅仅是一个执行这些功能的可执行文件;它本身是一个库,具有一个大型 API,可用于构建其他使用 Haskell 源代码的工具,例如 IDE 和分析工具。
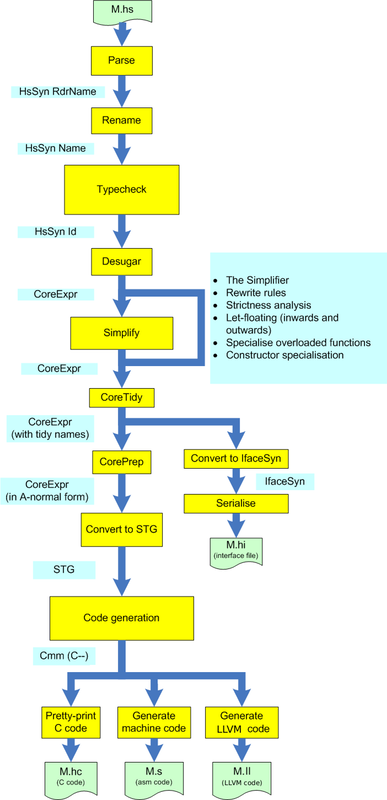
与大多数编译器一样,编译 Haskell 源文件是在一系列阶段进行的,每个阶段的输出都成为后续阶段的输入。不同阶段的整体结构如图 5.2 所示。
我们从传统的解析开始,它将 Haskell 源文件作为输入,并生成抽象语法作为输出。在 GHC 中,抽象语法数据类型 HsSyn 以它包含的标识符的类型为参数,因此抽象语法树的类型为 HsSyn t,其中 t 是标识符的某种类型。这使我们能够在程序通过编译器的各个阶段时向标识符添加更多信息,同时重用相同类型的抽象语法树。
解析器的输出是一个抽象语法树,其中标识符是简单的字符串,我们称之为 RdrName。因此,解析器生成的抽象语法的类型为 HsSyn RdrName。
GHC 使用工具 Alex 和 Happy 分别生成其词法分析和解析代码,它们类似于 C 的 lex 和 yacc 工具。
GHC 的解析器是纯函数式的。事实上,GHC 库的 API 提供了一个名为 parser 的纯函数,它接受一个 String(以及一些其他东西),并返回解析后的抽象语法或错误消息。
重命名是将 Haskell 源代码中的所有标识符解析为完全限定名称的过程,同时识别任何超出范围的标识符并适当地标记错误。
在 Haskell 中,模块可以重新导出从另一个模块导入的标识符。例如,假设模块 A 定义了一个名为 f 的函数,模块 B 导入模块 A 并重新导出 f。现在,如果模块 C 导入模块 B,它可以通过名称 B.f 引用 f,即使 f 最初是在模块 A 中定义的。这是一种有用的命名空间操作方式;这意味着库可以在内部使用任何它喜欢的模块结构,但通过几个重新导出内部模块标识符的接口模块公开一个干净整洁的 API。
然而,编译器必须解析所有这些,以便它知道源代码中的每个名称对应什么。我们清楚地区分实体,“事物本身”(在我们的例子中,A.f)和可以用来引用实体的名称(例如,B.f)。在源代码的任何给定点,都有一个范围内的实体集,并且每个实体可能由一个或多个不同的名称识别。重命名的任务是用对特定实体的引用替换编译器内部表示的代码中的每个名称。有时一个名称可以引用多个不同的实体;本身这不是一个错误,但如果名称实际被使用,那么重命名器将标记一个歧义错误并拒绝程序。
重命名以 Haskell 抽象语法 (HsSyn RdrName) 作为输入,并生成抽象语法作为输出 (HsSyn Name)。这里 Name 是对特定实体的引用。
解析名称是重命名的主要工作,但它也执行大量其他任务:将函数的方程收集在一起,并在它们具有不同的参数数量时标记错误;根据运算符的固定性重新排列中缀表达式;发现重复声明;为未使用的标识符生成警告,等等。
类型检查,正如你可能想象的那样,是检查 Haskell 程序是否类型正确的过程。如果程序通过类型检查器,那么它保证不会在运行时崩溃。(这里术语“崩溃”有一个正式定义,包括像“段错误”这样的硬崩溃,但不包括像模式匹配失败之类的事情。非崩溃保证可以通过使用某些不安全的语言特性来破坏,例如外部函数接口。)
类型检查器的输入是 HsSyn Name(具有限定名称的 Haskell 源代码),输出是 HsSyn Id。Id 是一个带有额外信息的 Name:特别是类型。事实上,类型检查器生成的 Haskell 语法完全用类型信息装饰:每个标识符都附带了它的类型,并且有足够的信息来重建任何子表达式的类型(这可能对 IDE 有用,例如)。
在实践中,类型检查和重命名可以交织在一起,因为 Template Haskell 特性在运行时生成代码,这些代码本身需要重命名和类型检查。
Haskell 是一门相当大的语言,包含许多不同的语法形式。它旨在易于人类阅读和编写——有各种各样的语法结构,让程序员在选择最适合当前情况的结构时有很大的灵活性。但是,这种灵活性意味着通常有几种方法可以编写相同的代码;例如,if 表达式在含义上与带有 True 和 False 分支的 case 表达式相同,并且列表推导符号可以转换为对 map、filter 和 concat 的调用。事实上,Haskell 语言的定义通过将所有这些结构转换为更简单的结构来定义它们;那些可以像这样被翻译掉的结构被称为“语法糖”。
如果所有语法糖都被删除,编译器会简单得多,因为随后需要处理 Haskell 程序的优化过程将需要处理更小的语言。因此,去糖化过程会删除所有语法糖,将完整的 Haskell 语法转换为一种更小的语言,我们称之为 Core。我们将在后面详细讨论 Core。
现在程序已经处于 Core 状态,优化过程开始了。GHC 的一大优势在于优化抽象层,所有这些工作都在 Core 级别进行。Core 是一种微小的函数式语言,但它是一个非常灵活的媒介,可以表达从非常高级别(例如严格性分析)到非常低级别(例如强度降低)的优化。
每个优化过程都接受 Core 并生成 Core。这里的主要过程被称为简化器,它的任务是执行大量保留正确性的转换,目标是生成更高效的程序。其中一些转换很简单明了,例如消除死代码或在被检查的值已知时减少 case 表达式,而另一些则更复杂,例如函数内联和应用重写规则(将在后面讨论)。
简化器通常在其他优化过程之间运行,大约有六个过程;实际运行哪些过程以及以什么顺序取决于用户选择的优化级别。
一旦 Core 程序被优化,代码生成过程就开始了。经过几个管理性步骤后,代码将走两条路线之一:要么被转换为字节码以供交互式解释器执行,要么被传递给代码生成器最终转换为机器码。
代码生成器首先将 Core 转换为一种称为 STG 的语言,它本质上只是用代码生成器需要的更多信息进行注释的 Core。然后,STG 被翻译成 Cmm,这是一种低级命令式语言,带有显式的堆栈。从这里,代码将走三条路线之一
Cmm 被转换为 LLVM 代码并传递给 LLVM 编译器。这种方式在某些情况下可以生成明显更好的代码,尽管它比原生代码生成器需要更长时间。在本节中,我们将重点介绍一些在 GHC 中特别有效的的设计选择。
| 表达式 | |||
| t,e,u | ::= | x | 变量 |
| | | K | 数据构造函数 | |
| | | k | 字面量 | |
| | | λ x:σ.e | e u | 值抽象和应用 | |
| | | Λ a:η.e | e φ | 类型抽象和应用 | |
| | | let x:τ = e in u | 局部绑定 | |
| | | case e of p→u | case 表达式 | |
| | | e ▷ γ | 强制转换 | |
| | | ⌊ γ ⌋ | 强制 | |
| p | ::= | K c:η x:τ | 模式 |
Core 的语法针对静态类型语言的编译器典型的结构是这样的:程序被类型检查,并转换为某种无类型的中间语言,然后进行优化。GHC 与众不同:它有一个静态类型中间语言。事实证明,这个设计选择对 GHC 的设计和开发产生了普遍的影响。
GHC 的中间语言称为 Core(在考虑实现时)或 System FC(在考虑理论时)。它的语法在图 5.3中给出。这里不需要关注确切的细节;感兴趣的读者可以参考 [SCPD07] 获取更多详细信息。但是,对于我们现在的目的,以下几点是关键
相比之下,Core 是一种微小、原则性、lambda 演算。它只有极少的语法形式,但我们可以将所有 Haskell 翻译成 Core。
相比之下,Core 是一种显式类型语言。每个绑定器都有一个显式类型,并且项包括显式类型抽象和应用。Core 享有非常简单、快速的类型检查算法,用于检查程序是否类型正确。该算法完全直截了当;没有特殊的折衷方案。
GHC 的所有分析和优化过程都作用于 Core。这很棒:因为 Core 是如此小的语言,优化只需要处理少数情况。尽管 Core 很小,但它非常有表现力——毕竟,System F 最初是作为一种用于类型化计算的基础演算而开发的。当新的语言特性被添加到源语言中时(这种情况经常发生),这些更改通常限制在前端;Core 保持不变,因此编译器的大部分也保持不变。
但是为什么 Core 被类型化了呢?毕竟,如果类型推断引擎接受源程序,那么该程序就可能被很好地类型化,并且每个优化过程都可能维护这种类型正确性。Core 可能享有快速的类型检查算法,但你为什么要运行它呢?此外,将 Core 类型化会带来显著的成本,因为每次转换或优化过程都必须生成一个类型正确的程序,而生成所有这些类型注释通常并非易事。
Core 类型检查器(我们称之为 Lint)是对编译器本身非常强大的一致性检查。想象一下,你写了一个“优化”,它意外地生成了将整数类型的值视为函数并试图调用的代码。很可能程序会产生段错误,或者以奇怪的方式在运行时失败。将段错误追溯到导致程序崩溃的特定优化过程是一个漫长的过程。现在想象一下,我们运行 Lint 经过每个优化过程(我们确实这样做了,如果你使用标志 -dcore-lint):它会在造成问题的优化之后立即报告一个精确定位的错误。真是太棒了。
当然,类型正确性并不等同于正确性:如果你将 (x*1) “优化”为 1 而不是 x,Lint 不会发出错误信号。但是,如果程序通过 Lint,它将保证在没有段错误的情况下运行;而且,在实践中,我们发现意外地编写类型正确但语义不正确的优化非常困难。
Lint 作为类型推断引擎的 100% 独立检查;如果类型推断引擎接受了一个实际上类型不正确的程序,Lint 将拒绝它。因此,Lint 充当类型推断引擎的强大审计员。Core 的存在也被证明是对源语言设计 的一项巨大健全性检查。我们的用户不断地建议他们希望在语言中添加的新功能。有时这些功能明显是“语法糖”,是对现有功能的便捷语法。但有时它们更深层,难以判断该功能的影响范围。
Core 为我们提供了一种精确评估这些功能的方法。如果该功能可以轻松地转换为 Core,这让我们确信没有发生任何根本性的变化:新功能类似于语法糖。另一方面,如果它需要扩展 Core,那么我们会更加谨慎地考虑。
在实践中,Core 一直非常稳定:在 20 年的时间里,我们只在 Core 中添加了一项新的主要功能(即强制转换及其关联的强制类型转换)。在同一时期,源语言发生了巨大变化。我们将这种稳定性归功于我们自身的智慧,而是归功于 Core 直接基于基础数学:向吉拉德致敬!
一个有趣的设计决策是类型检查应该在去语法糖之前还是之后完成。权衡如下
Core,人们可能会希望类型检查器会变得更小。Core 的设计进行一些妥协,以保留一些额外信息。大多数编译器在去语法糖之后进行类型检查,但对于 GHC,我们做出了相反的选择:我们检查完整的原始 Haskell 语法,然后对结果进行去语法糖。听起来好像添加一个新的语法结构可能很复杂,但(遵循法国学派)我们以一种使它变得容易的方式构建了类型推断引擎。类型推断分为两个部分
总的来说,在去语法糖之前进行类型检查的设计选择已被证明是一个巨大的成功。是的,它在类型检查器中增加了代码行,但它们是简单的代码行。它避免了对同一个数据类型赋予两个冲突的角色,并使类型推断引擎变得不那么复杂,并且更容易修改。此外,GHC 的类型错误消息非常好。
编译器通常具有一种或多种被称为符号表的数据结构,它们是将符号(例如变量)映射到有关该变量的一些信息的映射,例如它的类型或它在源代码中的定义位置。
在 GHC 中,我们非常谨慎地使用符号表;主要是在重命名器和类型检查器中。我们尽可能地使用另一种策略:变量是包含所有自身信息的数据结构。事实上,可以通过遍历变量的数据结构来访问大量信息:从一个变量中,我们可以看到它的类型,它包含类型构造函数,它包含它们的数据构造函数,它们本身包含类型,等等。例如,以下是一些来自 GHC 的数据类型(大量缩写和简化)
data Id = MkId Name Type
data Type = TyConApp TyCon [Type]
| ....
data TyCon = AlgTyCon Name [DataCon]
| ...
data DataCon = MkDataCon Name Type ...
一个 Id 包含它的 Type。一个 Type 可能是将类型构造函数应用于一些参数(例如 Maybe Int),在这种情况下,它包含 TyCon。一个 TyCon 可以是代数数据类型,在这种情况下,它包含其数据构造函数的列表。每个 DataCon 包含其 Type,它当然会提到 TyCon。等等。整个结构高度互联。事实上它是循环的;例如,一个 TyCon 可能包含一个 DataCon,它包含一个 Type,它包含我们开始的同一个 TyCon。
这种方法有一些优点和缺点
很难知道使用符号表是更好还是更差,因为设计的这个方面是如此基础,以至于几乎不可能改变。尽管如此,在纯函数式设置中避免符号表是一个自然选择,因此这种方法似乎是 Haskell 的一个不错的选择。
函数式语言鼓励程序员编写小定义。例如,以下是标准库中 && 的定义
(&&) :: Bool -> Bool -> Bool True && True = True _ && _ = False
如果每次使用此类函数都需要进行函数调用,那么效率将非常糟糕。一个解决方案是让编译器对某些函数进行特殊处理;另一个解决方案是使用预处理器将“调用”替换为所需的内联代码。所有这些解决方案都以某种方式令人不满意,尤其是因为另一个解决方案非常明显:只需内联函数即可。要“内联函数”意味着用函数体副本替换调用,并适当实例化其参数。
在 GHC 中,我们已系统地采用这种方法 [PM02]。实际上没有内置在编译器中。相反,我们尽可能地在库中定义,并使用积极的内联来消除开销。这意味着程序员可以定义自己的库,这些库将与 GHC 附带的库一样进行内联和优化。
结果是 GHC 必须能够进行跨模块内联,甚至跨包内联。这个想法很简单
Lib.hs 时,GHC 会在 Lib.o 中生成目标代码,并在 Lib.hi 中生成“接口文件”。此接口文件包含有关 Lib 导出的所有函数的信息,包括它们的类型和对于足够小的函数,它们的定义。Lib 的模块 Client.hs 时,GHC 会读取接口 Lib.hi。因此,如果 Client 调用在 Lib 中定义的函数 Lib.f,GHC 可以使用 Lib.hi 中的信息将 Lib.f 内联。默认情况下,GHC 只会将函数的定义公开到接口文件中,如果该函数“小”(有一些标志可以控制此大小阈值)。但我们也支持 INLINE 编译指令,以指示 GHC 在调用点积极地内联该定义,而不管其大小如何,因此
foo :: Int -> Int
{-# INLINE foo #-}
foo x = <some big expression>
跨模块内联对于定义超级高效的库至关重要,但它也有一定的代价。如果作者升级了他的库,重新链接 Client.o 与新的 Lib.o 不够,因为 Client.o 包含旧 Lib.hs 的内联片段,它们可能与新的 Lib.hs 不兼容。另一种说法是 Lib.o 的 ABI(应用程序二进制接口)以一种需要重新编译其客户端的方式发生了变化。
事实上,编译生成具有固定、可预测 ABI 的代码的唯一方法是禁用跨模块优化,这通常是为 ABI 兼容性付出的过高代价。使用 GHC 的用户通常可以访问其整个堆栈的源代码,因此重新编译通常不是问题(并且,正如我们将在后面描述的那样,包系统是围绕这种工作模式设计的)。但是,在某些情况下重新编译并不实用:例如,将库中的错误修复分发到二进制操作系统发行版中。将来,我们希望找到一种折衷方案,既能保持 ABI 兼容性,又能让一些跨模块优化得以进行。
一个项目能否生存下来往往取决于它的可扩展性。一个不可扩展的整体软件必须完成所有事情并做好所有事情,而一个可扩展的软件即使没有提供所有必需的功能,也可以成为一个有用的基础。
开源项目当然根据定义是可扩展的,因为任何人都可以获取代码并添加自己的功能。但是,修改由其他人维护的项目的原始源代码不仅是一种高开销的方法,而且也不利于与其他人分享你的扩展。因此,成功的项目往往会提供不涉及修改核心代码的可扩展性形式,GHC 也不例外。
GHC 的核心是一长串优化传递,每个传递都执行一些语义保留转换,将 Core 转换为 Core。但是库的作者定义的函数通常具有自身的一些非平凡的、特定于领域的转换,这些转换不可能被 GHC 预测到。因此,GHC 允许库作者定义在优化期间用于重写程序的重写规则 [PTH01]。通过这种方式,程序员实际上可以使用特定于领域的优化来扩展 GHC。
一个例子是 foldr/build 规则,它表示如下
{-# RULES "fold/build"
forall k z (g::forall b. (a->b->b) -> b -> b) .
foldr k z (build g) = g k z
#-}
整个规则是一个编译指令,由 {-# RULES 引入。该规则指出,只要 GHC 看到表达式 (foldr k z (build g)),它应该将其重写为 (g k z)。这种转换是语义保留的,但需要一篇研究论文来证明它 [GLP93],因此 GHC 不可能自动执行它。再加上其他一些规则和一些 INLINE 编译指令,GHC 能够融合列表转换函数。例如,(map f (map g xs)) 中的两个循环被融合为一个循环。
虽然重写规则简单易用,但它们已被证明是一种非常强大的扩展机制。十年前我们第一次在 GHC 中引入该功能时,我们预计它将是一种偶尔有用的工具。但在实践中,它在许多库中被证明很有用,这些库的效率通常严重依赖重写规则。例如,GHC 自身的 base 库包含 100 多条规则,而流行的 vector 库使用了几十条规则。
编译器提供可扩展性的一个方法是允许程序员编写一个直接插入编译器流水线的过程。这种过程通常称为“插件”。GHC 以以下方式支持插件
Core 到 Core 的过程编写为一个普通 Haskell 函数,例如在模块 P.hs 中,并将它编译成目标代码。-plugin P。(或者,他可以在模块开头的 pragma 中给出该标志。)P.o,将其动态链接到运行的 GHC 二进制文件中,并在流水线的适当位置调用它。但“流水线的适当位置”是什么?GHC 不知道,因此它允许插件做出决定。由于此原因和其他原因,插件必须提供的 API 比单个 Core 到 Core 函数复杂一点,但不多。
插件有时需要或产生辅助的特定于插件的数据。例如,插件可能会对正在编译的模块中的函数(例如 M.hs)进行一些分析,并且可能希望将这些信息放在接口文件 M.hi 中,以便插件在编译导入 M 的模块时可以访问该信息。GHC 提供了一种注释机制来支持这一点。
插件和注释是 GHC 的相对较新的功能。与重写规则相比,它们的进入门槛更高,因为插件正在操作 GHC 的内部数据结构,但当然它们可以做更多的事情。它们将被广泛使用还有待观察。
GHC 的最初目标之一是成为一个模块化的基础,其他人可以基于它进行构建。我们希望 GHC 的代码尽可能透明和有据可查,以便它可以作为他人进行研究项目的基石;我们想象人们会希望对 GHC 进行自己的修改,以添加新的实验性功能或优化。事实上,已经有一些这方面的例子:例如,存在一个带有 Lisp 前端的 GHC 版本,以及一个生成 Java 代码的 GHC 版本,这两个版本都是由与 GHC 团队几乎没有联系的个人完全独立开发的。
然而,生成修改后的 GHC 版本只代表了 GHC 代码可以重复使用的方式的一小部分。随着 Haskell 语言的流行,人们对理解 Haskell 源代码的工具和基础设施的需求越来越大,而 GHC 当然包含了构建这些工具所需的大量功能:Haskell 解析器、抽象语法、类型检查器等等。
考虑到这一点,我们对 GHC 做了一个简单的改变:不是将 GHC 构建成一个单片程序,而是将 GHC 构建成一个库,然后将其与一个小的Main模块链接起来,以创建 GHC 可执行文件本身,但也以库的形式提供,以便用户可以在自己的程序中调用它。同时,我们构建了一个 API 来将 GHC 的功能暴露给客户端。API 提供了足够的功能来实现 GHC 批处理编译器和 GHCi 交互式环境,但它也提供了对解析器和类型检查器等各个过程的访问,并允许检查这些过程生成的数据结构。这一变化催生了各种使用 GHC API 构建的工具,包括
包系统是近年来 Haskell 语言使用量增长的一个关键因素。它的主要目的是使 Haskell 程序员能够彼此共享代码,因此它是可扩展性的一个重要方面:包系统将共享代码库扩展到 GHC 本身之外。
包系统包含各种基础设施,这些基础设施共同使代码共享变得容易。以包系统为推动者,社区构建了大量共享代码;Haskell 程序员不再依赖于来自单个来源的库,而是利用整个社区开发的库。这种模式对其他语言也很有效;例如 Perl 的 CPAN,尽管 Haskell 是一种主要编译的而不是解释的语言,它呈现了一组略有不同的挑战。
基本上,包系统允许用户管理其他用户编写的 Haskell 代码库,并在自己的程序和库中使用它们。安装 Haskell 库就像说出单个命令一样简单,例如
$ cabal install zlib
从 http://hackage.haskell.org 下载 zlib 包的代码,使用 GHC 编译它,将编译后的代码安装到系统上的某个位置(例如,在 Unix 系统上的主目录中),并将安装注册到 GHC。此外,如果 zlib 依赖于任何尚未安装的其他包,则也会在 zlib 本身编译之前自动下载、编译和安装这些包。这是一种使用其他用户共享的 Haskell 代码库的极其便捷的方式。
包系统由四个组件组成,其中只有一个严格属于 GHC 项目
Cabal(构建应用程序和库的通用架构)的库,它实现了构建、安装和注册单个包的功能。cabal 工具,它将 Hackage 网站和 Cabal 库联系在一起:它从 Hackage 下载包,解析依赖项,并按正确的顺序构建和安装包。新包也可以使用命令行中的 cabal 上传到 Hackage。这些组件是由 Haskell 社区和 GHC 团队的成员在多年里开发的,它们共同构建了一个完美契合开源开发模式的系统。没有共享代码或使用他人共享的代码的障碍(当然,前提是您尊重相关的许可证)。您可以在 Hackage 上找到一个包后,在几秒钟内使用它。
Hackage 非常成功,以至于它现在剩下的问题都是规模问题:例如,用户发现很难在四个不同的数据库框架中进行选择。正在进行的开发旨在通过利用社区来解决这些问题。例如,允许用户对包进行评论和投票将使查找最佳和最受欢迎的包变得更容易,从用户那里收集有关构建成功或失败的数据并报告结果将帮助用户避免那些维护不善或存在问题的包。
运行时系统是一个主要由 C 代码组成的库,它被链接到每个 Haskell 程序中。它提供了运行编译后的 Haskell 代码所需的支持基础设施,包括以下主要组件
本节的其余部分分为两部分:首先,我们将重点介绍 RTS 设计中的一些我们认为已经取得成功并对它的良好运行起决定性作用的方面;其次,我们将讨论我们在 RTS 中为应对相当恶劣的编程环境而构建的编码实践和基础设施。
在本节中,我们将介绍 RTS 中两个我们认为特别成功的 design 决策。
垃圾收集器建立在块层之上,块层以块为单位管理内存,其中一个块的大小为 4 KB 的倍数。块层有一个非常简单的 API
typedef struct bdescr_ {
void * start;
struct bdescr_ * link;
struct generation_ * gen; // generation
// .. various other fields
} bdescr;
bdescr * allocGroup (int n);
void freeGroup (bdescr *p);
bdescr * Bdescr (void *p); // a macro
这是垃圾收集器用于分配和释放内存的唯一 API。内存块使用 allocGroup 分配,使用 freeGroup 释放。每个块都有一个与其关联的小结构,称为块描述符(bdescr)。操作 Bdescr(p) 返回与任意地址 p 关联的块描述符;这纯粹是基于 p 的值进行的地址计算,并编译成少量算术和位操作指令。
块可以使用 bdescr 的 link 字段链接在一起形成链,这是这种技术的真正威力所在。垃圾收集器需要管理多个不同的内存区域,例如世代,并且这些区域中的每一个都可能需要随着时间的推移而增长或缩小。通过将内存区域表示为块的链接列表,GC 从将多个可调整大小的内存区域放入平坦地址空间的困难中解放出来。
块层的实现使用了 C 的 malloc()/free() API 中众所周知的技术;它维护各种大小的空闲块列表,并合并空闲区域。操作 freeGroup() 和 allocGroup() 经过精心设计,可以达到O(1)。
这种设计的一个主要优势是它只需要很少的操作系统支持,因此非常便于移植。块层需要以 1 MB 为单位分配内存,并与 1 MB 边界对齐。虽然常见的操作系统都没有直接提供此功能,但在它们提供的功能的基础上实现起来并不困难。这样做的好处是,GHC 不依赖于操作系统使用的地址空间布局的特定细节,并且可以与地址空间的其他用户(如共享库和操作系统线程)和平共处。
块层在管理块链而不是连续内存方面存在少量前期复杂度成本。但是,我们发现这种成本在灵活性和平移性方面得到了超过的回报;例如,块层使并行 GC 的一种特别简单的算法得以实现 [MHJP08]。
我们认为并发是一种至关重要的编程抽象,尤其是在构建像 Web 服务器这样的应用程序时,这些应用程序需要同时与大量外部代理交互。如果并发是一种重要的抽象,那么它不应该太昂贵以至于程序员被迫避免它,或者构建复杂的架构来摊销它的成本(例如,线程池)。我们认为并发应该正常工作,并且足够便宜,以至于你无需担心为小型任务分叉线程。
所有操作系统都提供运行良好的线程,问题是它们太昂贵了。典型的操作系统难以处理数千个线程,而我们希望管理数百万个线程。
绿色线程,也称为轻量级线程或用户空间线程,是一种众所周知的技术,用于避免操作系统线程的开销。其理念是线程由程序本身或库(在我们的例子中是 RTS)管理,而不是由操作系统管理。在用户空间管理线程应该更便宜,因为需要更少的陷阱进入操作系统。
在 GHC RTS 中,我们充分利用了这个想法。上下文切换仅发生在线程处于 *安全点* 时,此时几乎不需要保存任何额外状态。由于我们使用精确的 GC,因此可以根据需要移动、扩展或缩小线程的堆栈。将其与 OS 线程进行对比,OS 线程中的每次上下文切换都必须保存整个处理器状态,并且堆栈是不可移动的,因此必须为每个线程预先保留一大块地址空间。
绿色线程可以比 OS 线程高效得多,那么为什么有人会想要使用 OS 线程呢?这归结为三个主要问题
事实证明,所有这些都很难用绿色线程来实现。然而,我们坚持在 GHC 中使用绿色线程,并找到了所有三个问题的解决方案
为了运行 Haskell 代码,OS 线程必须持有 *能力*:一个包含执行 Haskell 代码所需资源的数据结构,例如苗圃(创建新对象的空间)。一次只有一个 OS 线程可以持有给定的能力。(我们也称之为“Haskell 执行上下文”,但代码目前使用能力术语。)
因此,在绝大多数情况下,Haskell 的线程的行为与 OS 线程完全相同:它们可以进行阻塞的 OS 调用,而不会影响其他线程,并且它们可以在多核机器上并行运行。但它们在时间和空间方面都高效得多。
话虽如此,但实现确实存在用户偶尔会遇到问题,尤其是在运行基准测试时。我们上面提到过,轻量级线程从只在“安全点”进行上下文切换中获得了一些效率,编译器将代码中的这些点指定为安全点,此时虚拟机(堆栈、堆、寄存器等)的内部状态处于整洁状态,并且可以进行垃圾回收。在 GHC 中,安全点是在每次分配内存时,在几乎所有 Haskell 程序中,这都会定期发生,以至于程序在没有遇到安全点的情况下不会执行超过几十条指令。但是,在高度优化的代码中,有可能找到循环,这些循环运行许多迭代而不分配内存。这在基准测试中(例如,阶乘和斐波那契等函数)经常发生。在实际代码中,这种情况发生的频率较低,尽管确实会发生。缺少安全点会阻止调度程序运行,这会产生不利影响。有可能解决这个问题,但不会影响这些循环的性能,而且人们通常关心在内部循环中节省每个周期。这可能只是我们必须接受的折衷方案。
GHC 是一个拥有二十年历史的单一项目,并且仍在创新和发展中不断发酵。在大多数情况下,我们的基础设施和工具都是传统的。例如,我们使用错误跟踪器 (Trac)、维基 (也是 Trac) 和 Git 进行版本控制。(这种版本控制机制从纯手动演变而来,然后是 CVS,然后是 Darcs,最后在 2010 年迁移到 Git。)有一些点可能不太普遍,我们在这里提供它们。
在一个大型、长期项目中,最严重的困难之一是使技术文档保持最新。我们没有万能药,但我们提供了一种低技术机制,这种机制对我们特别有效:Notes。
在编写代码时,通常会有一个时刻,一个谨慎的程序员会在脑海里说类似“此数据类型有一个重要的不变性”的话。她面临着两种选择,这两种选择都不令人满意。她可以将不变性添加为注释,但这会使数据类型声明太长,以至于很难看到构造函数是什么。或者,她可以在其他地方记录不变性,并冒着它过时的风险。二十年来,*所有东西*都过时了!
因此,我们制定了以下非常简单的约定
Note [Equality-constrained types]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The type forall ab. (a ~ [b]) => blah
is encoded like this:
ForAllTy (a:*) $ ForAllTy (b:*) $
FunTy (TyConApp (~) [a, [b]]) $
blah
data Type = FunTy Type Type -- See Note [Equality-constrained types] | ...注释强调了一些有趣的事情正在发生,并给出了解释的注释的精确引用。这听起来微不足道,但精度远远超过了我们之前说“参见上面的注释”的习惯,因为通常不清楚指的是上面许多注释中的哪一个,几年后,注释甚至不在上面(它在下面,或者完全消失了)。
不仅可以从引用 Note 的代码转到 Note 本身,而且反过来也是可能的,这通常很有用。此外,同一个 Note 可以从代码中的多个点引用。
这种简单的 ASCII 仅技术,没有自动化支持,已经改变了我们的生活:GHC 大约有 800 个 Notes,并且数量每天都在增加。
GHC 的代码像十年前一样快速地变化,甚至更快。毫无疑问,系统的复杂性在这段时间内增加了许多倍;我们之前看到了 GHC 中代码量的一些衡量标准。然而,系统仍然是可以管理的。我们将其归因于三个主要因素
Core{} 数据类型很小,减少了 Core 到 Core 传递之间的耦合,以至于它们几乎完全独立,并且可以以任意顺序运行。作为额外的好处,纯函数式代码天生是线程安全的,并且往往更容易并行化。
回顾我们对 GHC 进行的更改,随着 GHC 的发展,一个共同的教训浮出水面:不完全是纯函数式,无论出于效率还是便捷性的目的,往往会在将来产生负面后果。我们有两个很好的例子
FastString 类型,它使用单个全局哈希表;另一个是全局 NameCache,它确保所有外部名称都被分配一个唯一的数字。当我们尝试将 GHC 并行化(即,使 GHC 在多核处理器上并行编译多个模块)时,这些基于变异的数据结构是 *唯一* 的障碍。如果我们没有在这些地方诉诸变异,GHC 的并行化将变得非常简单。事实上,尽管我们确实构建了一个并行版本的 GHC 原型,但 GHC 目前不包含对并行编译的支持,但这主要是因为我们还没有投入必要的精力来使这些可变数据结构线程安全。
当然,这些选项并非真正意义上的**常量**,因为它们在每次运行时都会发生变化,`opt_GlasgowExts` 的定义涉及调用 `unsafePerformIO`,因为它隐藏了一个副作用。尽管如此,这种技巧通常被认为“足够安全”,因为该值在任何给定的运行中都是常量;例如,它不会使编译器优化失效。
但是,GHC 后来从单模块编译器扩展到多模块编译器。在这一点上,使用顶层常量作为标志的技巧失效了,因为标志在编译不同模块时可能具有不同的值。因此,我们必须重构大量代码以显式地传递标志。
也许你会争辩说,首先将标志视为**状态**,就像在命令式语言中那样,可以避免这个问题。在某种程度上这是正确的,尽管纯函数式代码具有许多其他优点,其中最重要的是用一个不可变的数据结构表示标志意味着生成的代码已经是线程安全的,并且可以在不修改的情况下并行运行。
GHC 的运行时系统在许多方面与编译器形成鲜明对比。一个明显的区别是运行时系统是用 C 而不是 Haskell 编写的,但也有一些运行时系统特有的考虑因素导致了不同的设计理念。
运行时系统错误的症状通常与两种其他类型的故障难以区分:硬件故障,这种故障比你想象的更常见,以及对像 FFI(外部函数接口)这样的不安全的 Haskell 特性的误用。诊断运行时崩溃的第一项工作是排除这两种其他原因。
每一周期和每一个字节都很重要,但正确性更重要。此外,运行时系统执行的任务本质上是复杂的,因此正确性从一开始就很难实现。调和这些问题使我们采取了一些有趣的防御性技术,我们将在接下来的部分中进行描述。
运行时系统是一个复杂且充满敌意的编程环境。与编译器相比,运行时系统几乎没有类型安全。事实上,它的类型安全甚至比大多数其他 C 程序还要低,因为它正在管理数据结构,这些数据结构的类型位于 Haskell 层面,而不是 C 层面。例如,运行时系统不知道由 cons 单元尾部指向的对象是 `[]` 还是另一个 cons:此信息根本不存在于 C 层面。此外,编译 Haskell 代码会擦除类型,因此即使我们告诉运行时系统 cons 单元的尾部是一个列表,它仍然没有关于 cons 单元头部指针的信息。因此,运行时系统代码必须进行大量的 C 指针类型转换,而且它从 C 编译器那里几乎没有得到任何类型安全方面的帮助。
因此,我们在这场战斗中的第一件武器是**避免将代码放在运行时系统中**。在可能的情况下,我们将最少的功能放入运行时系统,并将其余部分写成 Haskell 库。这种情况很少出现问题;Haskell 代码比 C 代码健壮得多,也简洁得多,性能通常是可以接受的。决定在何处划定界线不是一门精确的科学,尽管在许多情况下这是相当清楚的。例如,虽然从理论上来说,用 Haskell 实现垃圾收集器是可能的,但实际上它非常困难,因为 Haskell 不允许程序员精确控制内存分配,因此为这种低级任务下降到 C 更有实际意义。
有很多功能不能(轻松地)用 Haskell 实现,在运行时系统中编写代码并不愉快。在下一节中,我们将重点介绍在运行时系统中管理复杂性和正确性的一方面:维护不变量。
运行时系统充满了不变量。其中许多是微不足道的,也很容易检查:例如,如果指向队列头部的指针为 `NULL`,则指向尾部的指针也应该为 `NULL`。运行时系统的代码中充满了断言来检查这些事情。断言是我们用于在错误显现之前找到错误的首选工具;事实上,当添加一个新的不变量时,我们通常会在编写实现不变量的代码之前添加断言。
运行时系统中的一些不变量要难得多,也难得多。这种贯穿整个运行时系统比其他任何不变量都多的不变量是以下内容:**堆中没有悬挂指针**。
悬挂指针很容易引入,并且在编译器和运行时系统本身中都有许多地方可能违反此不变量。代码生成器可能会生成创建无效堆对象的代码;垃圾收集器可能在扫描堆时忘记更新某些对象的指针。跟踪这类错误可能非常耗时(然而,这也是作者最喜欢的活动之一!),因为当程序最终崩溃时,执行可能已经从最初引入悬挂指针的地方进行了很长时间。有一些调试工具可用,但它们往往不擅长反向执行程序。(然而,最近版本的 GDB 和 Microsoft Visual Studio 调试器确实提供了一些对反向执行的支持。)
一般的原则是:**如果一个程序要崩溃,它应该尽快、尽可能大声地、尽可能频繁地崩溃。**(这句话来自 GHC 编码风格指南,最初由 Alastair Reid 编写,他参与了早期版本的运行时系统。)
问题是,无悬挂指针的不变量不是可以用常数时间断言检查的东西。检查它的断言必须对堆进行完整的遍历!显然,我们不能在每次堆分配后或每次 GC 扫描对象时运行此断言(事实上,这还不够,因为悬挂指针直到 GC 结束、内存被释放后才会出现)。
因此,调试运行时系统有一个可选模式,我们称之为**健全性检查**。健全性检查启用各种昂贵的断言,并且可以使程序运行速度慢很多倍。特别是,健全性检查在每次 GC 前后都运行对堆的完整扫描以检查悬挂指针(以及其他一些东西)。调查运行时崩溃的第一项工作是在开启健全性检查的情况下运行程序;有时这会比程序实际崩溃早很多就捕获到不变量违反。
在过去的 20 年中,GHC 消耗了作者大量的生命,我们对它的发展感到非常自豪。它并不是唯一的 Haskell 实现,但它是唯一一个被数十万人用来完成实际工作的实现。当 Haskell 被用来做一些不寻常的事情时,我们总是感到惊讶;一个最近的例子是 Haskell 被用来**控制垃圾车的系统**。
对于许多人来说,Haskell 和 GHC 是同义词:它从未打算如此,事实上,在许多方面,只有一种标准的实现是适得其反的,但事实是维护一个好的编程语言实现是一项大量的工作。我们希望我们在 GHC 中的努力,支持标准并明确界定每个独立的语言扩展,将使更多实现出现并与包系统和其他基础设施集成变得可行。竞争对每个人都有好处!
我们特别感谢微软给了我们机会,让我们能够将 GHC 作为研究的一部分进行开发,并将它作为开源软件进行分发。